

In case your time is short
- INOC's Ops 3.0 Platform is transforming NOC service delivery. Ops 3.0 is the third major iteration of INOC's platform, serving as a comprehensive operating system for technology, operations, and service delivery. It enhances NOC service delivery by automating the ingestion, correlation, and ticketing of alarm feeds, increasing accuracy and speed while minimizing human delays.
- The platform employs AIOps (AI for ITOps) to automate key tasks, prioritize incidents based on their business impact, and automatically generate incident tickets with enriched data for efficient resolution.
- Key features include automated alarm correlation, incident automation, self-service client portal, auto-resolution of short-duration incidents, and a secure multi-tenant architecture. These capabilities ensure rapid incident response, cost savings, and high availability.
- Ops 3.0 integrates seamlessly with various NMS platforms and ITSM tools, leveraging a robust CMDB and automated workflows to expedite action on incidents. This integration simplifies the incident management process, making it faster and more efficient.
- INOC's structured NOC approach, featuring an Advanced Incident Management team, ensures effective incident resolution and resource allocation. The onboarding process is tailored to align the platform with clients' unique operational needs, ensuring a seamless integration and customized service experience.
The platform of tools and systems for delivering service is a crucial factor in the success of any high-performance NOC. It’s what enables the NOC’s speed, accuracy, and consistency. At INOC, we’ve significantly invested in developing and refining our platform to deliver comprehensive NOC services to clients and partners 24x7x365.
Our latest and third major iteration of the platform is INOC Ops 3.0.
This platform serves as our operating system—the intersection of technology, operations, and service delivery. Its design enables us to ingest alarm feeds from various sources, auto-correlate those events into a single ticket, and present that ticket through a single pane of glass for efficient Incident, Problem, and Capacity Management.
In short, the Ops 3.0 platform enables our team to increase its accuracy and speed while reducing delays in human involvement. It frees NOC engineers to spend less time in the runbook and more time on strategic client projects.
What is Ops 3.0?
Before digging into the details, let's start by showing what Ops 3.0 is.
Below is a high-level schematic of the platform and how it connects to—and integrates with—a client's infrastructure and existing NMS, ITSM, and communications tooling.

Open larger image in new tab »
The workflow generally moves from the left to the right of the diagram as monitoring tools output alarm and event information from a client NMS or ours into our platform, where a number of tools process and correlate that data, generate incidents and tickets enriched with critical information from our CMDB, and triage and work them through a combination of machine learning and human engineering resources. ITSM platforms are integrated to bring activities back into the client's support environment and the system is integrated with client communications.
Our own Jim Martin puts is much more elegantly:
While our platform has many parts, its overall function can be summed up in just a few sentences:
- By understanding an alarm's business impact and severity, the Ops 3.0 platform automatically prioritizes incidents to ensure critical issues are addressed first.
- Machine learning and automation (AIOps) automate key tasks and gather and correlate data, making it actionable for human engineers.
- The AIOps toolset analyzes alarms and draws on an extensive Configuration Management Database (CMDB) to enrich that alarm data before correlating alarms and creating incident tickets.
- These tickets automatically attach Configuration Items (CIs) from the CMDB linked to the alarm data.
- The platform then automatically attaches recommended knowledge articles that provide key details for resolving incidents—pre-gathering the information engineers need before they begin to act on it.
- Our support team then troubleshoots or communicates with carriers, field services teams, advanced engineers, or other third parties to guide the incident through closure. This process enables network engineers to quickly identify the root cause and achieve high availability.
Here's a simplified visual representation of the platform to reflect the incident lifecycle:

Key Ops 3.0 Platform Capabilities
Our platform's five standout capabilities translate into immense value for our supported customers and partners.
Here's a brief overview of each of them.
1. Automated Alarm Correlation
Our platform uses machine learning to significantly reduce the time from initial alarm to incident ticket creation. This ensures that tickets are created for every event deserving of one, and nothing is missed. Our alarm experts carefully and continually monitor and fine-tune the platform’s machine learning, making us faster and more accurate when identifying issues as we gather more data.
2. Incident Automation
Our platform ingests alarms via our AIOps engine and enriches and correlates them with similar alarms to create a single incident ticket. Then, automated workflows assign or attach impacted CIs and differentiate the affected services or CIs from the likely cause of an incident. The system also attaches relevant knowledge articles for incident resolution. This level of incident automation is available on day one of service. Over time, we further automate repeatable tasks within the alarm-to-action guides and runbooks as we collect more actionable information, such as interface and log data.
3. Client Portal Self-Service
Our Service Portal offers several self-service functions, enabling you to interact directly with our platform. Ops 3.0 customers can request changes to their CIs and CMDBs, request portal accounts and updates to knowledge articles and procedures, and submit Scheduled Maintenances. We're continuously exploring additional opportunities to empower you to make direct changes to your information and data where appropriate.
4. Auto-Resolution of Short-Duration Incidents
Momentary disruptions can cause incidents that quickly resolve themselves, which can be a useless distraction for NOC engineers. To address this, we've added automation that automatically resolves any ticket that has alarms within a few minutes. This provides faster updates to our supported clients and reduces non-productive work for the NOC, allowing us to focus on critical ongoing issues. For clients utilizing our Problem Management service, all alarms that fall under this category are still reported on and reviewed by our Advanced Technical Services team as part of Problem Management.
5. Discrete, Secure Multi-Tenant Architecture
Ops 3.0 boasts an advanced multi-tenant architecture that provides customized solutions for each client's security needs. This architecture ensures the strict isolation of client data and network access, enabling efficient resource usage, swift deployment and updates, and a consistent client experience. Adhering to ISO 27001 standards, our platform offers a security-first approach, ensuring that our clients' data is efficiently managed and securely guarded.
Our multi-tenant architecture offers several advantages:
- First, shared resources and infrastructure make for a more effective use of resources, resulting in cost savings for our clients.
- Second, updates and new features can be deployed quickly and uniformly across all clients, ensuring that everyone benefits from the latest advancements in real time.
- Third, despite data segregation, the multi-tenant architecture guarantees that all clients receive the same level of performance, reliability, and user experience.
A High-Level Breakdown of Ops 3.0 Platform Components
Here's a brief dissection of each major component that makes up the Ops 3.0 platform.
Client or INOC NMS
Our platform allows for the ingestion of alarm and event information from your NMS infrastructure, enabling us to receive alarms from a simple network monitoring tool or a whole suite of monitoring tools (everything from application management to traditional network management to optical or physical layer management systems).
If you don’t currently use an NMS or aren’t satisfied with your instance, hosted solutions like LogicMonitor, New Relic, or iMonitor (our headless alarm management platform) are available.
Integrating these NMS tools with the AIOps platform ensures seamless alarm and event management—a key service differentiator.
Our platform integrates seamlessly with all major NMS platforms, including:
- SolarWinds
- LogicMonitor
- New Relic
- Nagios
- OpenNMS
- Dynatrace
AIOps
The core of our alarm and event management system is our AIOps engine, which utilizes machine learning to automate low-risk tasks and extract actionable insights from the vast amounts of data gathered across clients' supported environments.
Our AIOps tools correlate alarms from multiple sources, perform deep inspection of those alarms, and enrich them with additional metadata from our CMDB to expedite informed action.
Importantly, you can seamlessly integrate your existing infrastructure monitoring system with our AIOps toolset to retain the systems you already use while further maximizing those investments. This integration feeds alarms from your NMSs (or ours if needed) into our platform, streamlining alarm correlation, enrichment, and automatic ticket creation.
After a ticket is generated, our platform automatically identifies and attaches CIs from our CMDB, giving NOC engineers clear direction for investigation before any human intervention. The platform also supplies relevant knowledge articles and runbooks, facilitating fast, accurate diagnosis and action plan development.
CMDB
The INOC CMDB is the backbone of our NOC support service, enabling operational workflows and platform automations. Unlike basic CMDBs that contain only device or asset data, the INOC CMDB includes all essential information for AIOps to correlate events, create incident tickets, assess impact, and guide NOC engineers in resolving issues. This is why we prioritize creating and maintaining it throughout the service lifecycle.
Learn more about our CMDB in our explainer.
We ensure seamless integration of our CMDB with our clients' configurations, allowing us to associate the necessary meta information with every alarm and ticket. This equips our NOC engineers with the actionable information they need to make informed decisions. Additionally, we leverage our years of experience to enhance our clients’ existing CMDB structures and capabilities, further improving efficiency and effectiveness.
ITSM and Automated Workflows
Our platform's ITSM component, primarily ServiceNow, enhances automation capabilities by attaching CIs and records from the CMDB to incident tickets created by AIOps. This process automates initial impact assessment and provides NOC engineers with a likely set of issues and impacted service areas even before they touch the ticket.
The platform also automatically attaches knowledge articles and runbooks, enabling the NOC engineer to quickly access reference material for diagnosis and action plans, further increasing their efficiency.
TicketViewer
TicketViewer is an essential queue management system designed specifically for NOC engineers, helping them efficiently identify pending tasks in the queue and understand the corresponding SLAs in place.
TicketViewer also provides NOC management with a comprehensive overview, enabling effective resource allocation and ensuring that critical incidents receive the attention they deserve through a color-coded staging system that highlights ticket urgency.
The system also empowers NOC management with the capability to monitor and manage the performance of NOC engineers directly. It provides insights into individual and team response rates and problem-solving efficiency, enabling managers to identify bottlenecks and implement targeted improvements.
Client Integrations (ITSM and Communications)
In addition to integrating with your existing monitoring infrastructure, our platform also integrates with your existing ITSM tools, which improves the efficiency of incident resolution by identifying and attaching relevant configuration items and knowledge articles.
We integrate ticketing platforms bidirectionally so incidents can be passed from our platform to yours, where they can be actioned if needed. This creates a seamless, integrated support experience, allowing you to interact with tickets in your platform while receiving critical updates from ours.
We also integrate with communication tools to inform you of high-priority tickets and other critical updates.
Data Platform and Portal
All data collected from our AIOps engine, NMS instances, and ITSM toolset are sent to our data platform, where systems like Snowflake and Amazon Athena process and normalize it.
This data is then displayed in a client portal powered by our bespoke ServiceNow, with embedded Tableau reports providing actionable insights and comprehensive visibility into NOC performance and other related metrics.
Runbooks and Knowledge Base
Our runbooks integrate various functions and features of support operations, making them repeatable and easy to follow. These runbooks include process flow diagrams and detailed work instructions for various processes such as incident management, scheduled maintenance, change enablement, problem management, etc. Documentation about sites, infrastructure, connectivity, and other tools supports operational support processes and the CMDB.
We also develop alarm-to-action guides that focus on top alarms the NOC will receive, creating consistent knowledge articles and repeatable processes based on those alarms and alarm signatures. These resources enable us to achieve a high percentage of Tier 1 incident resolution.
As our support operation matures and learns more about each supported client environment, we’re continuously improving our automation capabilities—turning alarm-to-action guides and runbook procedure steps into automatable tasks that the platform can perform independently. Automating tasks such as collecting interface statistics or log data can further improve impact assessment and incident resolution times.
We also recognize that documentation is not static and must be updated as circumstances, personnel, regulations, business needs, and technologies change. That’s why we prioritize keeping our runbooks and documentation up-to-date, reflecting the organization's changing business and technology environments in a cyclical process to ensure effective and efficient support operations.
The Structured NOC
In addition to our platform, one of the key value components of our approach is our structured NOC. Our Tier 1 Service Desk handles inbound and outbound calls and emails and works towards resolving issues. But unlike other service providers, we position an Advanced Incident Management team (AIM), upstream to perform initial troubleshooting, even for Tier 1 service.
The AIM team is an extended function of our Tier 1 Service Desk, comprising senior troubleshooting staff within the Tier 1 team. This team conducts initial troubleshooting and creates an action plan after completing an investigation and impact analysis. This action plan drives everything that happens downstream. Every update we perform in the ticket is effectively its own handoff of that incident.
%20rev2-1.png?width=1094&height=600&name=INOC.COM%20%20NOC%20Best%20Practices_%2010%20Ways%20to%20Improve%20Your%20Operation%20in%202020%20(1)%20rev2-1.png)
By filtering everything through the AIM team, we avoid mistakes that may be made by less experienced engineers and prevent our Tier 1 staff from potentially spending hours trying to troubleshoot an issue that requires a more advanced engineer. The AIM team's role is critical in ensuring that incidents are managed effectively, and our approach ensures that issues are resolved without mistakes and that resources are allocated appropriately.
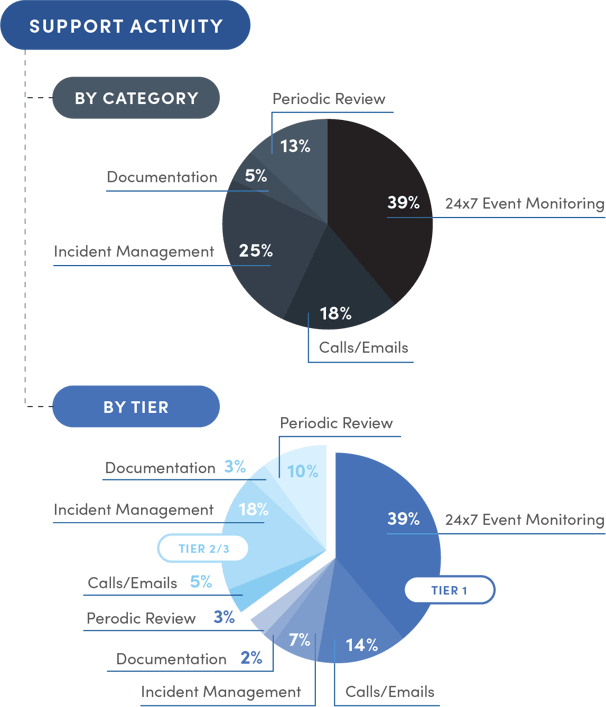
The graphic below illustrates how the Structured NOC radically transforms where and how support activities are managed—both by tier and category. In a matter of months, the value of an effective operational framework becomes abundantly clear as support activities steadily migrate to their appropriate tiers, lightening the load on advanced engineers while working and resolving issues faster and more effectively.
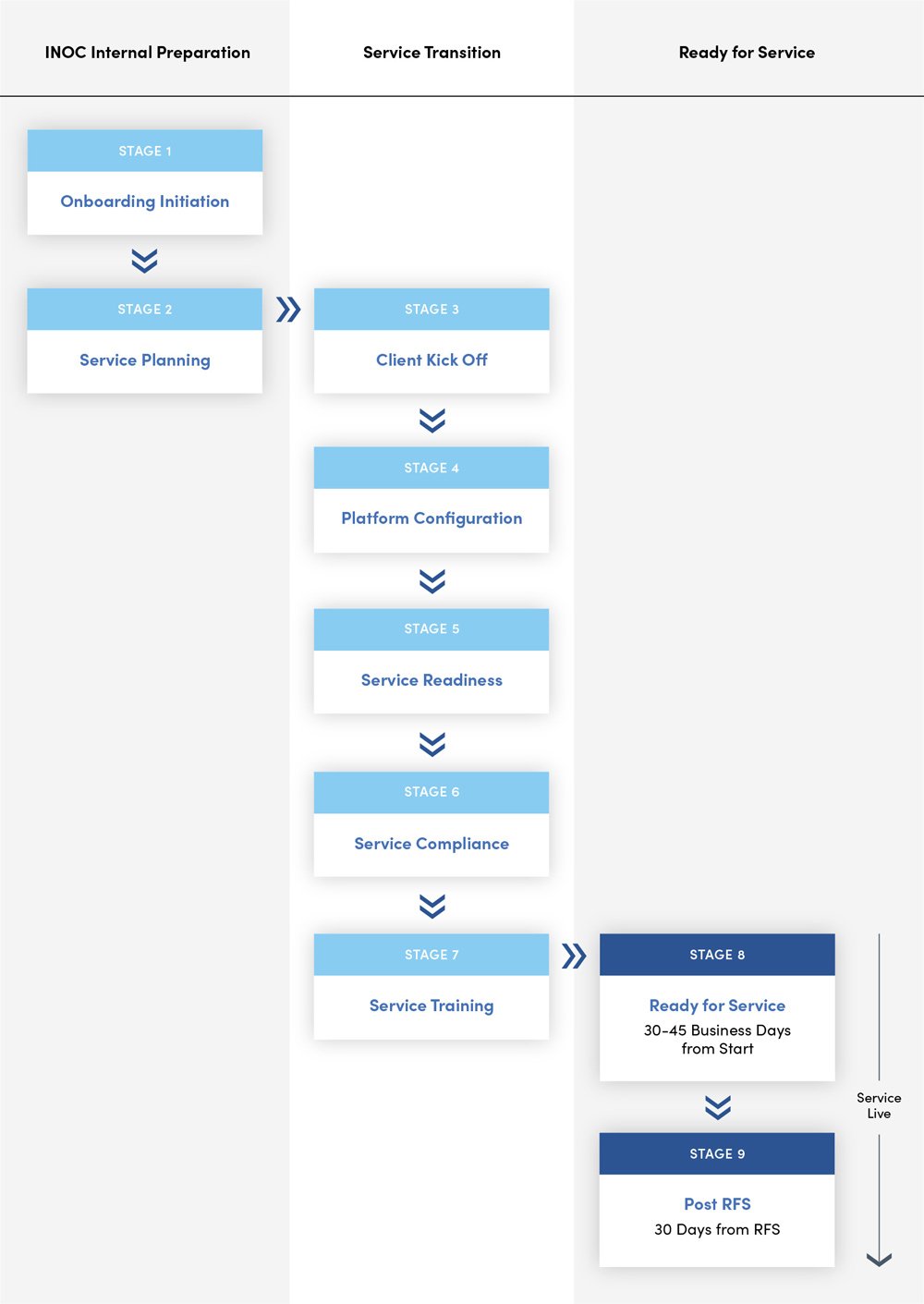
Onboarding to the Ops 3.0 Platform
The onboarding process is the foundational step towards ensuring that our platform aligns perfectly with our clients' unique needs and operational frameworks. We typically get clients up and running in just six to nine weeks.
At a high level, this process involves:
- Understanding your environment in extreme detail. We dive deep into understanding the client's existing network and systems, ensuring that our platform accurately represents every aspect.
- Setting the stage for customized service. Onboarding is more than just a technical exercise; it's about aligning our services with the client's operational goals and strategies. This ensures a service that is not only technically proficient but also strategically aligned with client objectives.
Here's an expanded look at each step of our typical onboarding process. Read our onboarding guide for more details.
The Importance of Populating Our CMDB From the Start
A well-populated CMDB is crucial for effective incident management. It provides our engineers with necessary insights into each component's role within the client's IT environment, enabling quicker and more accurate issue resolution.
Our CMDB enriches alarm data with critical metadata, allowing for a more nuanced understanding of incidents, and leading to more informed and effective responses. Understanding the business impact of each component and service allows the platform to prioritize incidents based on their potential impact on the client's operations, ensuring that critical issues are addressed promptly and efficiently.
The integration of business impact analysis within the CMDB framework ensures that every incident is not just seen through a technical lens but also from a business perspective. This approach ensures that the response to each incident is aligned with its potential impact on the client's business operations and objectives.
Our CMDB is not static; it evolves continuously with the client's changing IT landscape. Regular updates and reviews ensure that the CMDB accurately reflects the current state of the client's IT environment, maintaining the efficacy of the incident response and resolution processes.
Next-Level NOC Performance Outcomes
Here are just a few actual client results we've achieved with Ops 3.0 to date.
- INOC radically enhanced an industry-leading network OEM’s network operations, achieving a 30% auto resolution rate for incidents and reducing major escalations from 123 in 2022 to 18 in 2023. These operational improvements enabled the efficient onboarding of over 800 customers in six months, utilizing streamlined processes and AI-driven alarm correlation.
- INOC streamlined AT&T Business’s network operations across 260 sites by implementing AIOps for precise alarm correlation, reducing NOC support onboarding time from six weeks to just one week. This overhaul also decreased site escalations from nearly daily to just one per quarter, further supported by advanced operational reporting and self-service dashboards. Read the full case study.
- INOC transformed Aqua Comms’ network operations, significantly enhancing their NOC support's effectiveness, efficiency, and accuracy. This transformation led to a 20% reduction in ticket volume and establishing a well-defined professional services catalog for submarine and terrestrial cable networks. By refining runbooks and internal communications, INOC ensured clear, complete, and accurate alerts for customers and vendors and improved external notifications through executive summaries. The collaboration also achieved a tight SLA of five minutes from alarm detection to ticket creation, alongside solid second-line engagement, while stressing the importance of continual service improvement. Read the full case study.
- The collaboration between Adtran and INOC significantly improved Adtran's customer onboarding and service delivery, leading to a 100% on-time completion rate for onboardings, a 26% reduction in time-to-ticket, and a 50% decrease in NOC time-to-resolution. By restructuring the NOC service offering, implementing a dedicated quality management program, enhancing training, and standardizing onboarding procedures, the partnership addressed key challenges and improved overall service quality, increasing operational efficiency and customer satisfaction. Read the full case study.
- INOC, in partnership with SHI, significantly enhanced operational efficiency for a major financial company by addressing challenges with high support volumes and inadequate runbooks. Through the redefinition of support structures and improvements to runbooks, they achieved a 900% decrease in average MTTR, a 50% reduction in Time-to-Alarm (TTA), and a 70% rate of incident resolution by the NOC without escalation, all within a year. This transformation effectively reduced the support burden on the internal team and demonstrated the effectiveness of strategic NOC support and operational frameworks in optimizing IT infrastructure management. Read the full case study.
Final Thoughts and Next Steps
The Ops 3.0 Platform actively monitors infrastructure and applications in real time, 24x7, to identify faults, make actionable correlations, and prepare tickets for resolution without disrupting your team, your business, or your customers.
By applying AIOps to the NOC operations environment, we’ve removed the filters required to make analysis manageable for human engineers. With vastly superior data processing and machine learning power, we can instantly understand issues and identify the subtle indicators of approaching problems within a torrent of noisy data. For the first time, we’re able to start listening to what all of your data has to say about your environment and use those insights to deliver genuinely proactive NOC support.
Want to learn more about how the INOC Platform can help you achieve peak performance while saving your team valuable time and resources? Use our contact form or schedule a NOC consult to tell us a little about yourself, your infrastructure, and your challenges. We'll follow up within one business day by phone or email.
No matter where our discussion takes us, you’ll leave with clear, actionable takeaways that inform decisions and move you forward. Here are some common topics we might discuss:
- Your support goals and challenges
- Assessing and aligning NOC support with broader business needs
- NOC operations design and tech review
- Guidance on new NOC operations
- Questions on what INOC offers and if it’s a fit for your organization
- Opportunities to partner with INOC to reach more customers and accelerate business together
- Turning up outsourced support on our Ops 3.0 Platform






-images-0.jpg?height=2000&name=ino-WP-NOCPerformanceMetrics-01%20(1)-images-0.jpg)








-images-0.jpg?width=200&height=259&name=ino-WP-NOCPerformanceMetrics-01%20(1)-images-0.jpg)
