
In case your time is short
- AIOps is being applied in NOC to analyze massive data volumes, automate routine tasks, and predict issues before they arise, improving overall efficiency and response times.
- The top-performing NOCs also apply automation to handle low-risk, repetitive tasks, freeing up technical specialists for more complex and innovative work.
- When thoughtfully integrated and properly configured, AIOps tooling can correlate event data much faster and in higher fidelity than human engineers, identifying potential issues within vast data sets, leading to quicker and more proactive responses.
- The combination of automation and machine learning is transforming ITOps by streamlining processes, reducing manual intervention, and enhancing decision-making with better data analysis.
- AIOps in the NOC is shifting human roles from tedious, break-fix tasks to focusing on solving bigger problems and working on revenue-generating projects.
- While fully autonomous NOCs are not yet a reality, the progress towards more autonomous operations is clear, with current AIOps capabilities significantly improving NOC performance and operational challenges.
- Here at INOC, our AIOps engine is improving core NOC processes like event monitoring, incident management, problem management, and change management by providing better data analysis, reducing alert noise, and automating certain tasks for efficiency.
- AIOps is helping address significant operational challenges such as managing hybrid infrastructures, reducing alert noise, integrating siloed systems, and surpassing the limitations of traditional ITOM systems.
Watch our brief explainer to learn how we've integrated AIOps at key points in our NOC workflow and Ops 3.0 platform to dramatically improve service delivery.
Right now, troves of raw data sit in digital warehouses begging to be analyzed and distilled into clear instructions—instructions that would be more accurate and complete than a human engineer could ever be expected to create consistently. Instructions that would enable those humans to devote their attention to more important projects while helping to better prevent issues that threaten IT infrastructures and the businesses that rely on them.
AIOps—Artificial Intelligence for IT Operations—is already hard at work in the NOC doing just that. This very second, machine learning systems are plucking critical data points from the massive volumes of data generated across a typical IT environment and then marrying that data with automation to act on it—performing basic tasks that, until recently, only human engineers could do themselves.
For a few years now, INOC has been applying automation to take on the repetitive, low-risk tasks that pull technical specialists away from more important (and frankly more exciting) work. More recently, we've started started arming ourselves with vastly better data processing and machine learning power to augment and replace more—and more complex—manual tasks traditionally handled by humans.
Perhaps the most impactful recent advancement is AI-driven event correlation. We can now let machines correlate event data much faster than humans ever could and identify the subtle indicators of approaching issues within a torrent of otherwise noisy data. The outcome is measured in significantly faster and more proactive response rates—and thus, happier customers and end-users.
For example, here are just a few outcomes we've recently been achieving for our supported NOC clients thanks in part to our investments in applied AI and automation:
- A 30% auto-resolution rate for a leading network OEM, reducing major escalations and streamlining the onboarding of over 800 customers.
- A reduction in NOC support onboarding time from 6 weeks to 1 week for AT&T Business, significantly decreasing site escalations. (Read the full case study.)
- Enhancements in Adtran's NOC service offering, leading to a 26% reduction in time-to-ticket and a 50% reduction in time-to-resolution. (Read the full case study.)
- For Aqua Comms, a 20% reduction in ticket volume and a 5-minute SLO from alarm detection to ticket creation. (Read the full case study.)
- For SHI, a 10x decrease in average MTTR, underscoring our platform's ability to alleviate support burdens and improve resolution times. (Read the full case study.)
This combination of automation and machine learning brings the power and promise to genuinely transform how IT operations teams organize and operate. And as time goes on, automation will steadily continue to replace even more manual activities better suited for machines.
To assuage the lingering and understandable anxiety of human replacement, let’s be clear: the humans won’t be gone. They’ll just be freed from support tasks they’d likely rather not do anyway to focus on solving bigger problems and work on revenue-generating projects.
As a NOC service provider using these tools ourselves, we’re often asked whether it’s possible yet to build a fully autonomous or “dark” NOC. The answer today is still no. But the capabilities available today—the products of progress that have been made in pursuit of a more autonomous future—are already powerful enough to dissolve many of the human and technical limitations underpinning long-standing challenges to running a high-performing NOC operation. Short of a fully autonomous NOC, the value AIOps brings right now is immense and growing rapidly.
Here, we explain exactly how AIOps is helping NOC teams overcome some of the biggest operational challenges standing in their way right now. Rather than repeating the typical hype and hyperbole about AI, we bring the discussion down to earth and into the modern NOC, giving you a clear and concise explanation of AIOps in the NOC support context and what your organization likely stands to gain from applying its power to its support function.
📄 If you'd like a deeper dive into automation/AIOps in the NOC, we invite you to download our free white paper on the subject below or request a NOC consultation with our Solutions Engineering team.
Watch an excerpt of our webinar with BigPanda on how AIOps is being applied within the NOC (watch the full webinar here):
What is NOC Automation, Exactly?
First, a brief primer on the concept of automation in this context:
Machine learning enables us to expand what can be automated beyond the realm of the basic and repetitive. With its incredible processing power and the ability to “learn” as AI can, it automates—either fully or partially—more “knowledge-based” activities, such as:
- Correlating alarm data
- Generating and enriching tickets
- Managing notifications and escalations
Thinking Clearly About the Autonomous NOC
The promise of what AIOps might (and likely will) be able to do in the future can blur the expectations of what’s actually possible today.
Let’s be clear about what’s currently possible and what has yet to come:
While AIOps holds the power to deliver many new capabilities, the immediate applicability in NOC support takes the form of augmenting support processes by automating low-risk tasks and improving the accuracy of others.
Just how big of a role these tools can play is also an important point around which to set reasonable expectations. It might be tempting, for instance, to expect AIOps to run support operations autonomously. A full NOC operation—24x7 staff interacting with multiple internal teams, each offering a variety of skills and customer knowledge, and a network of third parties (cloud and SaaS providers, data centers, circuit providers, field support)—still plays a substantial role in maintaining infrastructure availability and performance to ensure customer satisfaction.
If a fully autonomous future is even possible, it’s far enough in the distance to disregard for now. Yet, as machine learning tools consume and process more data, they will inevitably become smarter and more capable, allowing for more in-depth analysis while pinpointing issues more quickly and predicting problems sooner.
New Solutions to Old Problems
A 2018 survey by 451 Research found that 64% of IT infrastructure teams saw their workloads increase from the previous year. Studies like this and our observations from speaking with IT professionals each day make it clear that as environments get larger and more complex, workloads continue to grow without a corresponding increase in the resources needed to manage them.
Part of the excitement surrounding AIOps isn’t just that machines can now take on this growing workload; it’s that the machines can do some of that work significantly better and faster than humans ever could, thereby solving some long-standing problems that have plagued NOCs for years.
One of those legacy problems is alarm noise. AIOps can analyze and correlate millions of data points—many more than any human team ever could—to dramatically improve the signal-to-noise ratio, reveal real problems, and intelligently group events to isolate the root causes.
Another legacy problem AIOps helps solve is outage prediction and prevention. With the ability to analyze so much data, AIOps can identify subtle anomalies and recognize patterns that would otherwise pass right through the fingers of human engineers. With their incredible processing speed, these tools can pick out subtle indicators of impending problems to help predict and prevent them before they occur. It’s a genuinely transformational capability that can save untold amounts of money in prevented outages.
Taken together, these capabilities remove the hurdles standing in the way of the NOC doing its primary job: improving uptime and performance, accelerating incident response, and preventing outages—all while simplifying the NOC operation itself.
How AIOps is Enhancing Core NOC Processes Today
Nearly every imaginable operational issue within the NOC is rooted in at least one of its foundational processes:
- Event Monitoring and Management;
- Incident Management;
- Problem Management, and
- Change Management.
A problem in any of these processes can trigger a cascade of issues that impede the NOC from doing its job in others.
For example, if the NOC can’t operate efficiently, Incident Management processes can’t be executed quickly to detect and fix issues. Connecting event data with past configuration changes becomes impossible. Ultimately, valuable opportunities to improve infrastructure and application availability and support operations are missed. The resulting costs are high, both in financial expense, customer reputation, and team morale.
By tapping into analysis capabilities that far exceed what even the best human experts can achieve and automating certain tasks, AIOps eliminates the underlying inefficiencies that cause so many operational problems while bringing a whole new level of data analysis capacities. The patterns it reveals within torrents of data across an entire IT environment aren’t vanity metrics; they provide clear, actionable intelligence to inform NOC support decisions.
Now, let’s unpack the value of AIOps by explaining what advantages it can bring to each of those core processes.
Event Monitoring and Management
AIOps can aggregate data from multiple data sources and multiple technology areas across the entire enterprise and provide a central data collection point. It can then analyze this data quickly and accurately to determine when multiple signals across multiple areas indicate a single issue.
We employ machine learning to significantly reduce the time from initial alarm to incident ticket creation. This ensures that tickets are created for every event deserving of one, and nothing is missed. Our alarm experts carefully and continually monitor and fine-tune the platform’s machine learning, making us faster and more accurate when identifying issues as we gather more data.
The resulting reduction in alert noise brings into focus those alerts that require action, helping reduce Time to Impact Analysis and thus Mean Time to Repair. Events can also be correlated with past configuration changes, allowing for faster, more reliable root cause determination.
Incident Management
AIOps can feed analysis into the Incident Management process by autonomously surfacing the probable cause and allowing the NOC engineer to confirm that the analysis and data are sound before implementing a plan for resolution.
The result? Faster incident analysis. When implemented cautiously and thoughtfully, AIOps can also automate responses and substantially reduce reduction times.
Perhaps one of the most exciting advancements our clients inherit is incident automation.
Once a root cause is determined with high confidence, a solution can often be automatically implemented if it’s available. Momentary disruptions can cause incidents that quickly resolve themselves, which can be a useless distraction for NOC engineers.
To address this, we've added automation that automatically resolves any ticket that has alarms within a few minutes. This provides faster updates to our supported clients and reduces non-productive work for the NOC, allowing us to focus on critical ongoing issues.
Our Ops 3.0 Platform ingests alarms via our AIOps engine and enriches and correlates them with similar alarms to create a single incident ticket. Then, automated workflows assign or attach impacted CIs and differentiate the affected services or CIs from the likely cause of an incident. The system also attaches relevant knowledge articles for incident resolution. This level of incident automation is available on day one of service.
Over time, we further automate repeatable tasks within the alarm-to-action guides and runbooks as we collect more actionable information, such as interface and log data.
Lastly, AIOps can issue predictive alerts when it correlates real-time event and performance data with past event data that resulted in outages to identify developing problems before they require a reactive response.
Problem Management
While the goal of Incident Management is to restore service quickly, Problem Management determines the root cause and finds a permanent solution to avoid the same incident in the future.
Root cause determination is typically resource-intensive, requiring hours of event and log data analysis. With access to multiple sources and massive amounts of data, AIOps can radically improve post-event root cause analysis.
AIOps can provide intelligent analysis—ranking events by their relationship to the original alert, noting anomalies, and suggesting possible causes—to streamline the Problem Management process. This capability allows the NOC engineer to more easily and confidently confirm the analysis, verify the data behind it, and then develop a solution.
Management
Maintenance events are common in the NOC. An effective AIOps implementation allows the automatic suppression of alarms when an infrastructure or application maintenance event is recorded. Automation will then only create tickets if appropriate after a maintenance window has been completed.
Alarms can be associated with the change by tying in the configuration item; this helps correlate future events with configuration changes. AIOps can also provide for deeper impact analysis by using relationship and topology data from multiple sources, such as the CMDB and monitoring tools, to help IT teams understand how a change on one node may propagate to other nodes, leading to a potentially undesired impact.
Lastly, by applying AIOps to historical change data, IT teams can get insight into the likely consequences before implementing a change. Changes can be given risk scores (such as low, medium, or high) to help quantify acceptable risk and inform the decision to deploy a change.
Overcoming Key Operational Challenges
In addition to looking at AIOps through the lens of what the NOC does, we can also understand its utility through the challenges it can help NOCs overcome.
Let’s explore five specific hurdles many modern organizations stumble over and how AIOps is poised to help with each.
1. Navigating hybrid, interrelated, and dynamic infrastructures
In today’s application-rich environment, systems have become more interdependent on one another. The result is a highly complex infrastructure ecosystem: a combination of traditional and cloud applications and infrastructure, along with technologies such as containerization, serverless computing, microservices, and orchestration tools.
Add in network technologies such as SND and NFV, and you’ll quickly find yourself in an environment with multiple devices and systems and high levels of interdependence to support various organizational services and applications. A single outage in these interrelated and interconnected environments can reduce organizational knowledge and prevent engineers from accessing needed systems.
Without good visibility, pinpointing the root cause of incidents—let alone understanding the overall impact of an outage that spans multiple environments—becomes impossible.
How AIOps can help
AIOps solutions can provide visibility into this complex interconnected environment by pulling together network, server, cloud, and application data into a single platform and analyzing topology, metrics, and traces for dependencies and correlations.
In addition, AIOps solutions can enable incident managers and NOC engineers to add operational and technical knowledge to the platform. When this is done using well-structured NOC processes and procedures, such platforms become truly useful in enhancing NOC support over time.
2. Reducing alert noise
NOC engineers typically field—and can often be overwhelmed by—both genuine alerts and many false positives. High alert noise distracts support teams from focusing on real issues. Over time, alert fatigue sets in. In the best case, the team takes a long time to find the actual issue. More than likely, however, too many alerts have the same effect as no alerts and are simply ignored.
Also, most threshold alerts are static. For example, an alert may be created if CPU usage is above 90% for five minutes. A lack of contextual awareness (batch job execution, for example) for threshold alerts leads to creating unnecessary incidents, adding to the NOC staff workload without improving infrastructure availability.
High alert volumes ultimately result in the same situation: higher MTTR and a poor reputation for the NOC, as the critical alerts are not acted on quickly.
How AIOps can help
Reduction in alert noise sharpens the alerts that require action, enabling the NOC team to focus on the right issue instead of spending time on false positives.
AIOps helps find the relevant correlated data in real time from this large volume of alerts, allowing the NOC engineer to focus on the right alerts at the right time. This allows the NOC to resolve the incident within the service level agreement (SLA)/service level objective (SLO) windows. Continued data collection allows for thorough analysis and Problem Management support later.
3. De-siloing systems and teams
The typical enterprise (or IT-complex) organization uses multiple tools to monitor and manage their complex environments, each collecting IT operations data and retaining that data in silos. (This may happen because DevOps teams use tools specific to their environment or because new tools are added when new technologies are adopted.)
With these separate data environments, it becomes very difficult to understand underlying infrastructure or application issues in current technology stacks with high levels of interdependence; siloed systems make centralized insight impossible.
Organizations expend significant resources to maintain these disparate systems yet continue to lack a single-pane view for monitoring and managing incidents. Typically, each support team within the organization will investigate issues independently. The NOC then combines these teams’ tools and processes, eventually coalescing the data and analysis to determine the root cause. This leads to significant delays in incident resolution. Senior management escalation and involvement in troubleshooting are common in these siloed environments, causing significant loss of productivity for the organization.
How AIOps can help
Reduction in alert noise sharpens the alerts that require action, enabling the NOC team to focus on the right issue instead of spending time on false positives.
AIOps helps find the relevant correlated data in real time from this large volume of alerts, allowing the NOC engineer to focus on the right alerts at the right time. This allows the NOC to resolve the incident within the service level agreement (SLA)/service level objective (SLO) windows. Continued data collection allows for thorough analysis and Problem Management support later.
4. Breaking through the limitations of traditional ITOM systems
Traditional ITOM systems depend on an accurately populated CMDB with clearly defined relationships and dependencies between parent and child configuration items.
However, in most support organizations, the CMDB quickly becomes out of date, given the usually incomplete implementation of reliable change management processes and procedures. Thus, depending on the CMDB when executing NOC processes such as Event Monitoring and Management and Incident Management is fraught with inaccuracies.
How AIOps can help
AIOps allows organizations to preserve existing investments in ITOM tools and bring together data from diverse sources for processing and correlation. It can further enrich the information on alerts with data from NOC runbooks.
How We've Integrated AIOps and Automation Into Our NOC Support Platform: Ops 3.0
The platform of tools and systems for delivering service is a crucial factor in the success of any high-performance NOC. It’s what enables the NOC’s speed, accuracy, and consistency. At INOC, we’ve significantly invested in developing and refining our platform to deliver comprehensive NOC services to clients and partners 24x7x365.
Our latest and third major iteration of the platform is INOC Ops 3.0.
This platform serves as our operating system—the intersection of technology, operations, and service delivery. Its design enables us to ingest alarm feeds from various sources, auto-correlate those events into a single ticket, and present that ticket through a single pane of glass for efficient Incident, Problem, and Capacity Management.
In short, the Ops 3.0 platform enables our team to increase its accuracy and speed while reducing delays in human involvement. It frees NOC engineers to spend less time in the runbook and more time on strategic client projects.
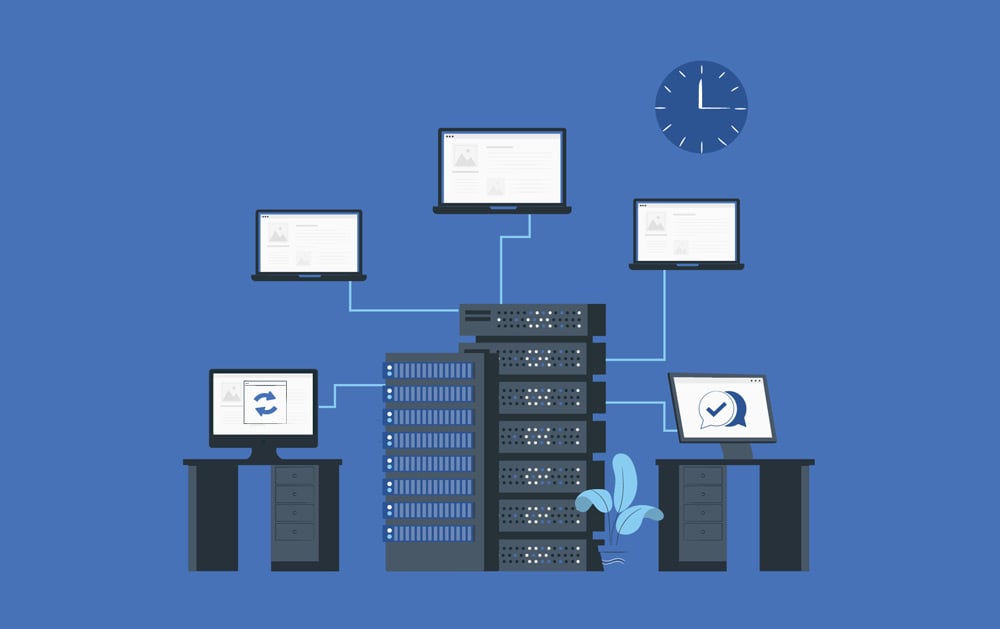
Below is a high-level schematic of the platform and how it connects to — and integrates with — a client's infrastructure and existing NMS, ITSM, and communications tooling.

Open larger image in new tab »
The workflow generally moves from the left to the right of the diagram as monitoring tools output alarm and event information from a client NMS or ours into our platform, where a number of tools process and correlate that data, generate incidents and tickets enriched with critical information from our CMDB, and triage and work them through a combination of machine learning and human engineering resources. ITSM platforms are integrated to bring activities back into the client's support environment, and the system is integrated with client communications.
While our platform has many parts, its overall function can be summed up in just a few sentences:
- By understanding an alarm's business impact and severity, the Ops 3.0 platform automatically prioritizes incidents to ensure critical issues are addressed first.
- AIOps automates key tasks and gathers and correlates data, making it actionable for human engineers.
- The AIOps toolset analyzes alarms and draws on an extensive CMDB to enrich that alarm data before correlating alarms and creating incident tickets.
- These tickets automatically attach Configuration Items (CIs) from the CMDB linked to the alarm data.
- The platform then automatically attaches recommended knowledge articles that provide key details for resolving incidents—pre-gathering the information engineers need before they begin to act on it.
- Our support team then troubleshoots or communicates with carriers, field services teams, advanced engineers, or other third parties to guide the incident through closure. This process enables network engineers to quickly identify the root cause and achieve high availability.
Here's a simplified visual representation of the platform to reflect the incident lifecycle:

At the core of INOC's platform is a powerful AIOps engine that serves as a sort of central nervous system for alarm, event, and incident management. This system leverages machine learning to automate routine tasks and extract meaningful insights from vast datasets. It performs multifaceted analysis, including alarm correlation across various sources, deep alarm inspection, and data enrichment using CMDB information, enabling more informed and rapid response to incidents.
Here's a quick list of the key ways we've AIOps and automations into our Ops 3.0 platform—reiterating many of the points we've covered in this guide:
1. Automated Alarm Correlation
INOC's platform uses advanced machine learning to streamline the alarm-to-ticket process. This system rapidly analyzes incoming alarms, ensuring that every significant event generates a ticket without unnecessary duplication. The platform's efficiency improves over time through continuous fine-tuning by alarm experts, leading to faster and more accurate issue identification across diverse client environments.
2. Incident Automation
The Ops 3.0 platform employs a sophisticated AIOps engine to process alarms comprehensively. It enriches alarm data, correlates related issues, and automatically generates detailed incident tickets. The system intelligently assigns relevant Configuration Items, distinguishes between affected services and root causes, and attaches pertinent knowledge articles. This automation is available immediately upon service initiation and evolves to handle increasingly complex tasks as it learns from each client's unique operational patterns.
3. Auto-Resolution of Short-Duration Incidents
To optimize NOC efficiency even further, our platform automatically resolves transient incidents—an innovation we have not observed elsewhere in the market. Tickets generated from alarms that clear within minutes are automatically closed, reducing noise and allowing NOC engineers to focus on more critical, ongoing problems. This not only streamlines operations but also provides clients with rapid updates on brief disruptions without unnecessary escalation.
4. Ticket Creation and Enrichment
Our platform's ITSM/ticket management system goes beyond basic creation to provide context-rich incident reports. By automatically linking relevant Configuration Items from the CMDB and attaching appropriate knowledge articles and runbooks, the system equips NOC engineers with comprehensive information before they even begin to investigate. This proactive approach significantly reduces initial response times and improves the accuracy of initial assessments.
5. ITSM Integration
Ops 3.0 seamlessly integrates with ITSM tooling to enhance automation throughout the incident lifecycle. This integration allows for automatic attachment of Configuration Items and CMDB records to incident tickets, facilitating rapid impact assessment. By providing NOC engineers with a preliminary analysis of likely issues and affected service areas, the system enables more informed and swift responses to incidents.
6. Data Processing, Analysis, and Reporting
The Ops 3.0 platform collects information from multiple sources, including the AIOps engine, CMDB, NMS, and ITSM tools. This data is processed and normalized using sophisticated systems like Snowflake and Amazon Athena. The resulting insights are presented through a user-friendly client portal, offering actionable intelligence and comprehensive performance metrics to both INOC's team and clients.
7. Continuous Improvement of Automation
Our approach to automation is dynamic and evolving. As our platform gains "experience" by collecting data and refining its rulesets with each client's environment, it continuously improves its automation capabilities. This includes transforming manual processes from alarm-to-action guides and runbooks into automated tasks. By progressively automating routine operations like data collection and initial diagnostics, the platform becomes increasingly efficient and effective over time.
8. Integration with Client Systems
Flexibility and compatibility are key features of the Ops 3.0 platform—and key drivers that motivate teams to partner with us for NOC support. The platform integrates seamlessly with a wide array of client systems, including various NMSs, ITSM platforms, and communication tools. This comprehensive integration ensures a unified approach to incident management, allowing for smooth information flow between INOC's platform and client systems without replacing desired client-side tooling or processes.
9. Business Impact Analysis
The platform leverages its robust CMDB to provide context-aware incident management. By understanding the business significance of various components and services, the system can prioritize incidents based on their potential impact on client operations. Critical issues receive immediate attention, aligning technical responses with business priorities and improving overall service quality.
Final Thoughts and Next Steps
Effective use of automation and machine learning technologies depends on understanding where to apply them within the multiple processes that a NOC supports.
- Event Monitoring and Management is the obvious starting point, with AIOps helping reduce alert noise at the event analysis stage.
- Incident Management is enhanced when AIOps suggest the probable cause.
- With the ability to analyze historical event, incident and performance data, AIOps can identify possible root causes in support of Problem Management.
A successful AIOps initiative provides customers with a much-improved experience, but implementation requires a strong foundation in NOC best practices and a well-developed organizational structure. This includes good knowledge management and training practices.
For AIOps solutions to become more intelligent and truly useful over time, resulting in a more automated NOC, domain expertise—operational and technical—needs to be “encoded” into the tools; logic needs to be reviewed, tested against results, and refined constantly. A continual service improvement program that includes quality control and assurance and detailed operational and technical reporting insight is key to getting good value from the AIOps solution.
A centralized monitoring and incident response team can serve as experts and offer high-quality support to dynamic organizations. Such a team can provide centralized management of these tools, developing standard responses—including automation—to incidents using AIOps where possible. Proper application of AIOps in the NOC can reduce event noise, help identify and resolve incidents quickly, and prevent problems from impacting customers
Wondering how your organization can benefit from AIOps? Download our free white paper to learn more about what we cover here and get a worksheet you can use to contextualize the advantages. When you’re ready to take the next step, reach out to schedule a time to talk through these insights and opportunities.

Free white paper The Role of AIOps in Enhancing NOC Support
Download our free white paper and learn how your NOC support stands to gain from AIOps by overcoming operational challenges and delivering outstanding service. Use the free included worksheet to contextualize the value of AIOps for your organization.






-images-0.jpg?height=2000&name=ino-WP-NOCPerformanceMetrics-01%20(1)-images-0.jpg)







-images-0.jpg?width=200&height=259&name=ino-WP-NOCPerformanceMetrics-01%20(1)-images-0.jpg)
