

In case your time is short
- Prevent Downtime with Reliable Systems: Emphasize designing both the physical components and support operations of optical systems to enhance reliability and prevent downtime.
- Importance of MTTR and MTBF: Utilize Mean Time to Recovery and Mean Time Between Failures as metrics to measure system reliability from both hardware and support perspectives.
- Proactive Planning: Encourage network operations center teams to proactively plan for failures by understanding their systems and maintaining essential spares like transponders, optics, and amplifiers.
- Vendor Selection and Maintenance: Choose quality vendors and understand their maintenance schedules, ensuring service agreements include provisions for spare parts availability.
- Documentation and CMDB: Stress the importance of proper documentation and using a Configuration Management Database to improve response times and accuracy in handling incidents.
- Performance Monitoring: Implement robust systems for monitoring performance to aid in prioritizing incidents and understanding network health over time.
- Signal Flow Diagrams: Use signal flow diagrams to quickly identify and address issues within the physical network infrastructure.
- Training and Knowledge Sharing: Regularly update training and knowledge bases to keep pace with advances in optical technology and ensure staff proficiency.
- Cleaning Network Alarms: Address long-standing alarms and "noise" in the network to prevent minor issues from escalating into major problems.
- Outsourcing Benefits: Consider outsourcing optical network monitoring and management to experienced NOC providers to leverage their expertise and resources for improved network performance and problem resolution.
Preventing downtime is one of the primary objectives of optical system design.
The best way to prevent downtime is to design reliable systems. In this case, a “system” includes both the physical components within the network and the support operation that keeps it running at peak performance.
Mean time to recovery (MTTR) and mean time between failures (MTBF) are two useful metrics for evaluating a system's reliability from both perspectives.
To achieve the shortest possible MTTR and longest possible MTBF, support teams—namely the network operations center (NOC)—need to closely examine their optical systems and plan for eventual failure in the devices and in the network from the start.
Selecting a quality vendor and understanding the standard maintenance schedules is key. The details of a maintenance agreement are critical but often overlooked. For example, a strong service agreement should ensure that the vendor will have spares in inventory and ship them out to whatever location needs them.
It’s also smart to maintain your own set of spares in an easily accessible storage facility. The key to maintaining your own spares is knowing what can fail and what can impact your network. Transponders, optics, amplifiers, processors, cross-connect modules, and fiber jumpers should be maintained. Most filters, although key to a network, are passive devices and rarely fail.
Here, we outline eight tips that can directly improve MTTR and MTBF in optical networks. The first five tips focus on simple (but again often overlooked) preventive actions teams can take to maximize MTBF. The final three tips are more involved from an IT service management (ITSM) perspective—they focus on improving MTTR when incidents do occur.
Need a NOC support partner with extensive experience and deep optical expertise? INOC takes optical infrastructure support to the next level. Having worked on hundreds of optical fiber networks, we improve performance and solve problems before they affect customers or end-users. Learn more about our NOC services and request a free NOC consultation to explore possible support solutions.
1. Keep Your Air Filter Clean
Temperature plays a huge role in the longevity of electronic equipment. Keeping air filters clean is the most underperformed function in any data center.
Replacing or cleaning the filter every three months is highly encouraged.
2. Keep Your Data Center Clean
Depending on a device's location, a data center may be very clean or it could be a storage closet shared with a broom, mops, and other cleaning materials.
If possible, designate a separate storage room for devices. If a cleaning closet is the only location available, keep that location as clean as possible.
3. Keep Records of Key Optical Levels
Once you’ve installed optical components such as amplifiers, OSCs, and transponders, ROADMs should be stable, and a baseline level should be recorded.
Ideally, these values would barely change over the lifetime of your network. However, due to adds, deletes, maintenance, fiber cuts, and human error, these values can change pretty radically—and have a major impact on the performance of your network.
With a baseline recorded value of key components, you can track down where issues occur so they can be easily corrected.
4. Keep Things Clean During Installation
During an initial optical installation, properly cleaning the optics and bulkhead connectors is an absolute must. Cleaning and scoping the optic and the bulkhead connectors can eliminate a significant amount of issues.
Here are a few examples of dirty optics:
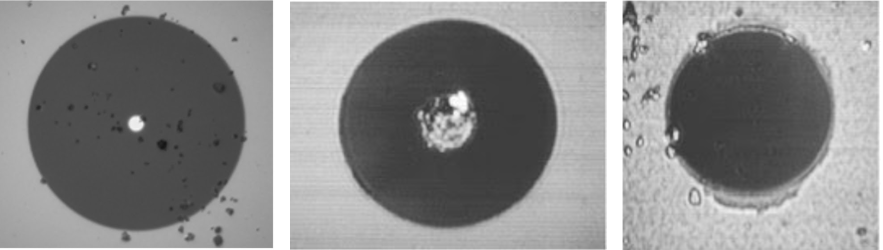
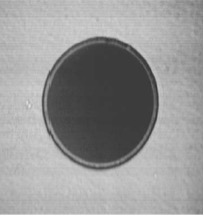
Here’s an example of how an optic and connector should appear before installation:
5. Have Spare Modules and Components in Storage or Easily Accessible
If and when a module fails, having spares on hand to reduce downtime is critical. This may cost a little more upfront, but the investment in minimizing downtime when a module fails is well worth it from a business perspective.
This can be difficult when trying to keep a network under a budget, so evaluating key components to determine the absolute minimum spares needed to maintain network uptime is a helpful step to take during the initial design phase.
6. Put Necessary Documentation in Place and Make it Accessible
The first five tips focused primarily on preventive steps teams can take to maximize MTBF. Our final three focus on the operational side of IT service management and minimizing MTTR when incidents do occur. From this perspective, perhaps the most important area is documentation.
Generally speaking, documentation is one area where just about every support team can find room to improve. The most common problem we see—de-prioritizing or outright ignoring seemingly insignificant documentation practices—can add up to cause a major drag on operational efficiency, hurting MTTR when incidents occur.
Often, the optical documentation teams have is partially or fully outdated. Circuits have moved, equipment has been decommissioned. Things have changed in the network, but the processes and workflows used to manage them aren’t kept up to date. It’s easy to miss just how much of a difference having current documentation and making it accessible without needing to hunt for it can make on core KPIs like MTTR.
We’ve broken documentation down into three areas in particular:
- the configuration management database (CMDB);
- performance monitoring values, and
- signal flow diagrams.
Configuration Management Database (CMDB)
Just about every team responsible for managing optical networks can radically improve its response times and accuracy by arming itself with a CMDB commensurate with the size and complexity of its infrastructure.
This database should enable the NOC or other support operation with all the relevant information related to the tickets they receive so engineers can spend their time taking action rather than hunting down and writing up the basic information an automated system is fully capable of handling itself.
In short, a CMDB should make your team faster, not slower. It should condense and simplify the steps to get necessary incident information, not add more complexity. It should help MTTR, not hurt it.
That requires thoughtfulness about how you operationalize a CMDB in your workflow. Here at INOC, for example, we’ve implemented logic and automation to auto-attach CMDB records based on the alarm, device, IP address, and facility.
Taking advantage of automation enables us (and could enable any team) to quickly and accurately present all the optical networking information the NOC needs to make informed decisions without having to manually track that information down. Prior to this CMDB automation, it wasn’t unusual to take as long as three hours per ticket to investigate and identify the issue and notify the appropriate party. Today, that entire process has been shortened to 15 to 30 minutes.
“When you talk about driving MTTR down, a big part is being able to identify the impact and identify who needs to be involved in driving it from that point forward. That’s where a lot of teams fall down—and where a lot of time gets spent. Having a CMDB and being smart about how you use it to improve your workflow can make an enormous difference. Part of what makes our CMDB so powerful, and why we can deliver at such demanding service levels, is the automation and intelligence we've put behind it. The logic and auto-attach features are the results of years spent iterating it into the super-efficient system it is today.”
— Austin Kelly, Director of Dedicated NOC and ATS, INOC
The value of such an investment isn’t hard to see; it translates into virtually instant service recognition. As soon as a NOC engineer opens a ticket, they find a CI link already prepared for them with the specific circuit or number of circuits affected, as well as the carrier circuit affected. This enables an engineer to do two things very quickly:
- First, they know immediately which carrier to engage so they can make that call as fast as possible.
- Second, they can immediately notify customers or end-users with any necessary information. Again, in most cases, this is done in less than 30 minutes.
“Before we implemented the CMDB we have today, it could take hours to manually dig into the issue to determine what and where it was and which customers or end-users were affected. Only then could you start crafting emails to those affected. It was a long time before you had what you needed to make a call to a carrier. The way we're doing it now, most of that is automated. There's some logic tied into it to auto-attach those and return them. So instead of three hours, you're typically sitting anywhere between 15 to 30 minutes before you're actually calling somebody to get them engaged to help resolve an issue.”
— Austin Kelly, Director of Dedicated NOC and ATS, INOC
Performance monitoring values
Another area of documentation that’s often weak or missing despite its potential impact on MTTR is performance monitoring values—specifically, the ability to define and store those values to give the NOC up-to-date, real-time information about what incidents are most vital at any point in time so they can be prioritized.
Monitoring the performance of the NOC enables teams to not only react to incidents better, but also understand historical trends, spot patterns and anomalies, and reveal the need for infrastructure changes that would prevent problems in the future.
A robust monitoring system collects and aggregates incoming data, stores it, and visualizes metrics in a way that makes them useful to support teams.
Signal flow diagrams
A CMDB can quickly inform teams of the what, where, and who. But it doesn't reveal the full path of the physical infrastructure affected so engineers can trace a channel or an optical issue throughout the chassis and then out onto the outside plant.
Signal flow diagrams provide these critical visual references. When paired with the alarm information provided by the CMDB, teams can quickly identify where they suspect the issue is located, decreasing the time it takes to dispatch and isolate faults.
7. Make Sure Training is Commensurate With Your Optical Technology and Staff Have a Knowledge Base to Reference
If documentation is the first “bucket” of operational improvement, training and knowledge sharing is the second. Simply put, optical technology advances fast enough to require near-constant knowledge updating.
But many organizations don’t account for this operationally. The knowledge that is retained is siloed in the heads of perhaps just a few individuals. And worse, those who are “in the know” don’t update their brains as fast as they update their optical networks—eventually finding themselves over their skis with systems they’re not familiar with.
“When purchasing optical networks, some organizations prioritize the latest-and-greatest over the most stable systems that may be a few years old. If the people responsible for caring for these networks aren’t up to speed on how these new technologies work, there’s a whole host of risks that can quietly emerge in the background—only to make themselves known when things go wrong and it’s not clear what’s been affected or how to remedy the situation.”
— Austin Kelly, Director of Dedicated NOC and ATS, INOC
Fixing this problem requires organizations to be intentional about making training and knowledge sharing (via a knowledge base) a core component of their broader operation.
That’s a whole other discussion unto itself, but suffice it to say that if training and knowledge sharing aren't already in place, the benefits of outsourcing part of all of your NOC to a third-party service provider that has made it core to its operation may be well worth it. More on that point here.
“Outsourcing optical support to a NOC that’s well-trained and knowledgeable about both older and bleeding-edge technologies offers direct access to a whole team of people that have the knowledge, ability, and documentation already in place. Everything is nice and packaged and there’s continuing education to support the networks and identify new types of issues. That’s a huge reason many of our clients with optical networks decide to work with us.”
— Austin Kelly, Director of Dedicated NOC and ATS, INOC
8. Clean Your Noisy or “Unkept” Network by Addressing Long-Standing Alarms
The third common operational issue we see and solve in optical networks is, for lack of a better term, "noise."
An organization will purchase a network, get it implemented, start running it, and perceive things to be going well. Over time, they’ll start to experience alarms on the network. Some may be major alarms, many others minor. These smaller ”hiccups” may not affect traffic and are therefore ignored. Sometimes teams configure their monitoring systems only to inform them when something critical is happening that affects their services.
Over time, the open issues that underlie months or even years of unchecked alarms leave the optical network “noisy” and the business that much more vulnerable to outages and downtime. Here at INOC, we’ve routinely conducted comprehensive “clean up” projects for organizations finding themselves in this situation.
For those interested in cleaning up their own networks or considering having a support partner help, that process involves cataloging the unresolved alarms, investigating and addressing them as well as evaluating the overall health of the system. Contact us to learn more about how we can help.
“One of the organizations we’ve assisted with this had been ignoring span loss alerts. It simply wasn’t treated as something worth addressing until service was down. But this issue was directly impeding the NOC’s ability to resolve issues. A fiber cut would occur outside the plant and our NOC wouldn’t be able to tell if it was a legitimate issue that needed to be dispatched, or if it was normal behavior—all because the system was run unchecked for several months. Those span loss values were completely outdated or lost. Baselines had been modified. No documentation existed. The NOC couldn’t discern whether an alarm was real or not. Cleaning up the seemingly minor alarms can prevent a situation like this.”
— Austin Kelly, Director of Dedicated NOC and ATS, INOC
The Value-Adds of Outsourcing Optical Network Monitoring and Management with INOC
Here at INOC, the size, scope, and capability of our NOC team—and the support teams that support them—provide a level of optical service that can be difficult and cost-prohibitive to achieve in-house.
Having worked on hundreds of optical fiber networks, we help enterprises, communication service providers, and OEMs improve performance and solve problems before they affect customers or end-users. Our engineers offer deep expertise in a wide range of optical network technologies, including 10 Gigabit Ethernet (GigE), 10 Gigabit SONET, OCx ATM, any protocol—SONET, Ethernet, FibreChannel—over DWDM, GPON, and other technologies such as MPLS, PBB and OTN.
We support the optical platforms of a variety of equipment manufacturers, including Cisco, Juniper, Ciena, Alcatel-Lucent, Infinera, and Adtran.
“With a 24x7 NOC monitoring the network around the clock, we can take effective action immediately upon an alarm going off, whether it's two o'clock in the morning or two o'clock in the afternoon. We have people with eyes on it and the ability to respond across all three tiers of support. We're able to troubleshoot very difficult and very unique issues.”
— Austin Kelly, Director of Dedicated NOC and ATS, INOC
A Brief Introduction to INOC's Ops 3.0 Platform
INOC's Ops 3.0 Platform is transforming NOC service delivery. Ops 3.0 is the third major iteration of our NOC service platform, serving as a comprehensive operating system for technology, operations, and service delivery. It enhances NOC service delivery by automating alarm feed ingestion, correlation, and ticketing, increasing accuracy and speed while minimizing human delays.

- Automation and AIOps: The platform utilizes AIOps (Artificial Intelligence for IT Operations) to automate the ingestion, correlation, and ticketing of alarm feeds. This automation enhances NOC service delivery by increasing accuracy and speed and reducing human intervention.
- Key Features: Features include automated alarm correlation, incident automation, a self-service client portal, auto-resolution of short-duration incidents, and a secure multi-tenant architecture. These capabilities ensure rapid incident response, cost savings, and high availability.
- Integration and Efficiency: Ops 3.0 integrates seamlessly with various NMS and IT ITSM tools, leveraging a robust CMDB and automated workflows to expedite incident management—simplifying and speeding up the process.
- Structured NOC Approach: An Advanced Incident Management team within the structured NOC ensures effective incident resolution and optimal resource allocation. The onboarding process is customized to align the platform with clients' unique operational needs for seamless integration and service.
- Outcomes: Implementing Ops 3.0 has led to significant operational improvements for clients, including increased incident auto-resolution rates, reduced major escalations, and streamlined processes for customer onboarding and network operations.
Want to put our optical network expertise to work for you? Request a free NOC consultation or use our general contact form to tell us a little about yourself, your infrastructure, and your challenges. We'll follow up within one business day by phone or email. And be sure to download our free white paper below for a look at the top challenges in running a successful NOC—and how to solve each of them.

Free white paper Top 11 Challenges to Running a Successful NOC — and How to Solve Them
Download our free white paper and learn how to overcome the top challenges in running a successful NOC.






-images-0.jpg?height=2000&name=ino-WP-NOCPerformanceMetrics-01%20(1)-images-0.jpg)








-images-0.jpg?width=200&height=259&name=ino-WP-NOCPerformanceMetrics-01%20(1)-images-0.jpg)
