

In case your time is short
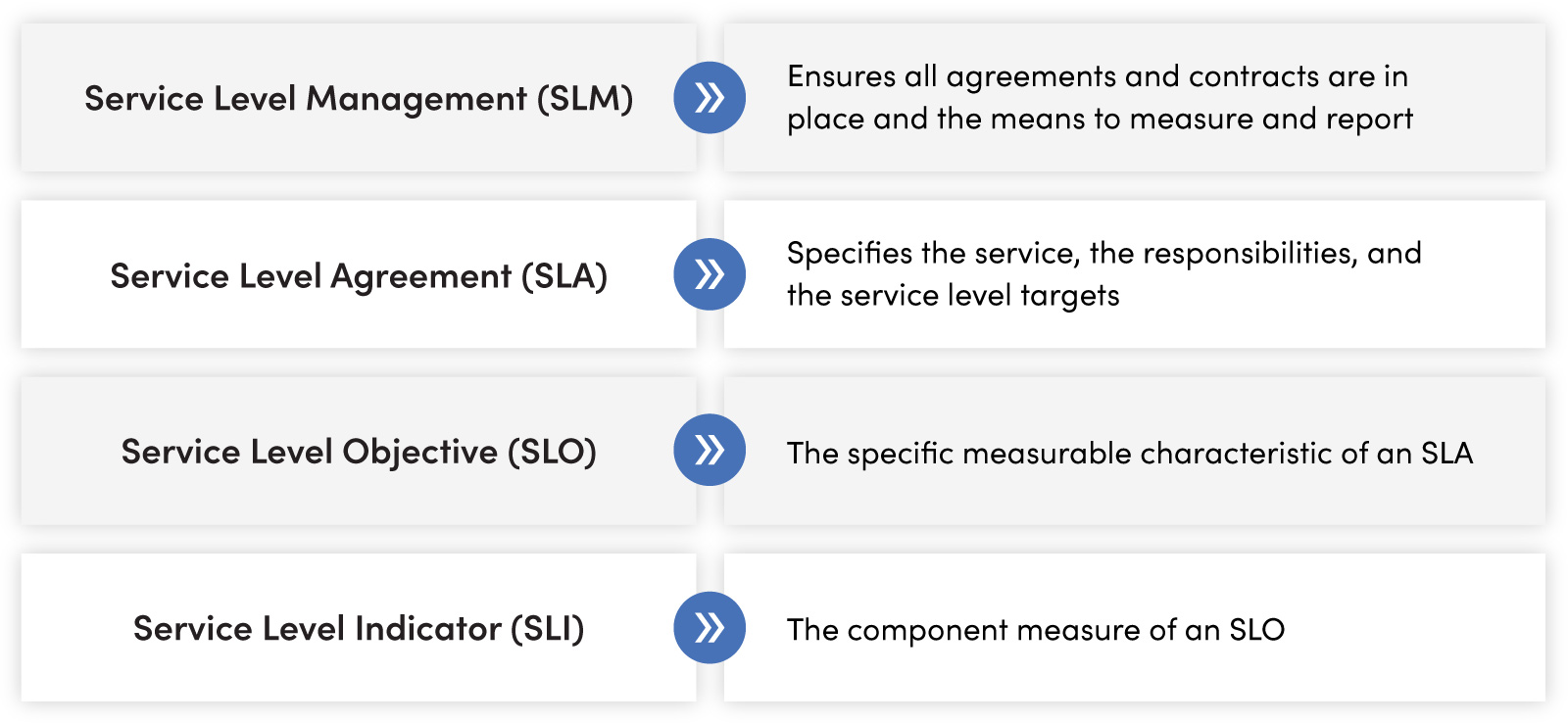
- Foundational Concepts: Service Level Agreements (SLAs) and Objectives (SLOs) are critical in establishing expectations between NOC service providers and clients. SLAs are contractual and SLOs serve as non-binding goals.
- Importance of Reporting: Regular SLA/SLO reporting is vital for ensuring compliance, improving service delivery, and maintaining customer transparency and accountability.
- Advanced Reporting Approaches: Beyond basic compliance, advanced reporting delves into granular performance analysis, highlighting areas for improvement and enabling proactive problem management.
- Best Practices: Effective reporting involves breaking down SLAs/SLOs into component parts, selecting appropriate tools for monitoring/reporting, automating repetitive tasks, and conducting regular client review meetings.
- Examples of Reports: Detailed reports on metrics such as Time-to-Acknowledge (TTA), Time-to-Resolve (TTR), Time-to-Notify (TTN), and Time-to-Close (TTC), along with SLA exclusions and change metrics, provide comprehensive insights into NOC performance.
A Service Level Agreement (SLA) is a contractual agreement between service providers and clients outlining the level and quality of services that will be provided. A Service Level Objective (SLO) is an agreement between service providers and clients outlining the level and quality of services provided. These aren’t contractually binding and don’t include penalties.
SLAs and SLOs provide essential details like services to be offered, the metrics for measuring service levels, remedies or penalties for non-compliance, and many more. These agreements act as a safety net for both parties, ensuring a clear understanding of the service expectations and performance measurements.
Monitoring and reporting on SLA/SLOs is an essential aspect of service management in the Network Operations Center (NOC). It provides crucial insights into the performance of a NOC service provider against agreed parameters, helping both parties to ensure the SLA/SLO is being adhered to. Effective monitoring and reporting give teams the insights they need to promptly identify and address non-compliance, avoid service disruptions, and maintain service quality.
In this guide, we explain the basics of SLA/SLO reporting in the NOC, lay out some best practices from our own operation, and give some example reports from our own reporting program.
Talk to us to learn more about our approach to service level management and reporting.
📄 Read our other guide—NOC Service Level Agreements: A Guide to Service Level Management—for an introduction to managing service levels in the NOC.
Why is SLA/SLO Reporting Important?
Before establishing SLA/SLO reporting in the NOC, it’s important to review why doing so is critical.
Here are some of the well-known and somewhat obvious reasons:
-
Ensuring compliance with SLA/SLO commitments. Regular and rigorous service level reporting and review makes sure these commitments are being met consistently. Given the potential impact of service disruptions, this function is particularly critical within a NOC environment.
-
Enabling teams to identify areas to improve service delivery. Service level metrics provide valuable insights into service delivery inefficiencies, bottlenecks, or issues that may not be apparent without pretty granular tracking. In a NOC environment, pouring over precise reporting can drive improvements in various areas that otherwise the company would have been blind to—whether that's identifying and resolving network incidents faster, enhancing communication processes for better client engagement, or any other dimension of service that can be tracked. By looking closely at individual SLOs, as we do at INOC, we can fine-tune each aspect of service delivery for optimal performance.
-
Building trust and accountability with customers. Regular reporting ensures transparency, demonstrating to clients that the NOC is fulfilling its commitments and operating reliably and professionally. Accountability is another key point; good reporting shows that the NOC takes its commitments seriously and is willing to hold itself accountable for its performance.
In addition to these, there are a few other less-obvious ways SLA/SLO reporting has an impact.
Let’s walk through them in a little more detail.
Setting reasonable expectations for service delivery
A crucial but often overlooked aspect of service level reporting in the NOC is managing expectations between the NOC and its customers or end-users. Here at INOC, for example, it’s not uncommon for the teams we work with to assume SLA/SLOs apply per ticket, which results in misunderstandings down the road.
In a 24/7 NOC environment, particularly in the shared NOC model we use with many clients, ensuring all tickets are addressed within the SLA/SLO timeframe is impractical. There may be situations when multiple high-priority incidents (P1s) occur simultaneously, but due to the limitations in staffing, not all can be attended to with equal urgency. In such scenarios, while every effort is made to respond swiftly, handling incidents at the same speed is not always feasible.
This brings up an important aside about distinguishing between an SLA and an SLO. We’ll let our own Pete Prosen do the talking:
“An SLA is a contractual obligation with potential financial penalties for non-compliance. In contrast, an SLO is a commitment to do the best possible within given constraints but without associated financial penalties.
Most companies are unwilling to pay the extra cost associated with a financial penalty component, which would require the NOC to maintain higher staffing levels that would require very high costs. Therefore, they typically prefer to have an SLO in place to gauge how well the service provider is doing.
This method of measurement might bring to light significant network issues. For example, if clients expect ten outages a month and experience 150, they might question the higher ticket counts compared to their previous NOC provider. Effective reporting can reveal the reality of the network's state, shedding light on aspects such as average recovery time or average ticket handling time.
Ultimately, the objective is to provide clear upfront expectations. Teams need to understand what they're signing up for, whether it's an SLA or SLO, and what level of service they're paying for. Regular reporting on whether these expectations are met is critical to maintaining client satisfaction and trust.
Even if there's a financial penalty associated with the SLA, clients may choose not to enforce it if they perceive their time-to-resolution has improved or remained satisfactory. Nevertheless, monitoring the commitment and service level provides them with a higher-level view of how the NOC operates.”
— Peter Prosen, VP of NOC Operations, INOC
Fully revealing what’s happening in your network
Comprehensive reporting from the NOC paints a much more complete picture of what’s actually happening in a network from one day to the next. This wealth of data can be analyzed and leveraged to identify potential issues within the network, even those that might not be immediately apparent or causing current disruptions.
Granular insight like this gives teams incredibly valuable starting points for problem management, highlighting areas or specific devices that may not be in alarm, but deserve further investigation or intervention. By detecting and dealing with these potential problems early on through our own reporting, we routinely help our clients preemptively mitigate issues that could otherwise cause significant disruptions in the future.
An example could be a recurring alarm on a particular site. By filtering out the noise from other sites and focusing solely on the specific site, the NOC team might notice a repeating alarm—something like an "ambient sensor failure." Even if this alarm isn't causing any immediate operational issues, it's still worth investigating because of its frequency.
Once this anomaly is identified, it's time to get the person with the right expertise involved—someone who understands what that specific alarm means for the network device in question. The specialist can then assess the situation, diagnosing whether the alarm is indicative of a more significant underlying issue that needs to be addressed. Over time, being able to see impending problems before they actually become problems makes life much easier for everyone involved.”
— Peter Prosen, VP of NOC Operations, INOC
Granular insight like this gives teams incredibly valuable starting points for problem management, highlighting areas or specific devices that may not be in alarm, but deserve further investigation or intervention. By detecting and dealing with these potential problems early on through our own reporting, we routinely help our clients preemptively mitigate issues that could otherwise cause significant disruptions in the future.
Enabling data-driven prioritization in the NOC
The vast amount of data flowing into the NOC can be overwhelming, so the ability to prioritize tasks effectively becomes critical. Prioritization in this context means focusing resources and efforts on the most urgent or impactful issues, reducing the risk of being overly reactive to less pressing problems.
— Peter Prosen, VP of NOC Operations, INOC
What Should NOC SLA/SLO Reports Cover?
Since NOCs are typically the nerve centers for network troubleshooting, system updates, and communication routing, maintaining a high service level is a top priority. An SLA/SLO for a NOC will typically cover aspects such as network uptime, issue resolution times, and response times for different incidents.
Given the specific nature of the services provided by NOCs, their SLA/SLO reports typically cover a few specific dimensions of service, including:
-
Response Times: This measures how quickly the NOC responds to reported issues or incidents. This metric, also known as Time to Acknowledge (TTA), is vital since swift response times can mitigate potential network damage or downtime.
-
Average and Maximum Hold Times for Calls: These metrics reveal service levels of the NOC's support line, measuring the average and maximum wait time before a call is answered. This is crucial for maintaining customer satisfaction and ensuring issues are addressed promptly. Occurrences of unusually long wait times (e.g., 2 hours due to system errors) need to be identified and resolved.
-
Notification and Escalation Metrics: These capture the efficacy of the NOC's procedures for notifying relevant parties about incidents and escalating issues that can't be immediately resolved. Rather than just timing these processes, it's equally, if not more essential to assess the number of incidents requiring escalation to a higher tactical level or back to the equipment provider. The goal is to handle as many incidents as possible at Tier 1, reserving higher tiers for more complex problems and strategic projects.
-
Equipment and Carrier Metrics: For organizations with diverse networks, they might need to know how often incidents are escalated to different equipment providers or carriers. This can inform future purchasing decisions, highlighting which products are more reliable or which carriers are more responsive and quick to fix issues.
-
Troubleshooting Windows: This metric refers to the time taken by the NOC to troubleshoot and resolve an issue. A shorter troubleshooting window is preferred as it minimizes downtime and facilitates faster return to normal operations.
-
Auto-resolve Instances: This occurs when an issue resolves itself before a ticket is addressed by the NOC. The auto-resolve mechanism can hide tickets from the NOC when the issue alarms and then clears quickly. However, these tickets become visible again when the issue recurs. This process can influence the timing metrics, especially TTA, as NOC technicians may not see the ticket for some time.
An Advanced Approach to SLA/SLO Reporting
At INOC, we understand that maintaining a high Service Level Management (SLM) standard for our goes beyond meeting the agreed-upon KPIs and SLA/SLOs. We also realize that restricting ourselves to a limited set of rigid service levels does not give a holistic view of the quality of the NOC service, nor does it allow for true continuous improvement. That’s why we take an advanced approach to SLM, combining critical KPI reporting with a broader set of SLOs.
Our reporting model places equal importance on the composite metrics and the individual components that make up those metrics. We dive deep into each SLO, break it into its components, and measure each element. This approach offers a more detailed insight into the actual performance, enabling us to identify specific areas of improvement.
For example: consider the critical NOC SLO of Mean Time to Restore (MTTR) with a set target of four hours. This metric comprises several smaller Service Level Indicators (SLIs) including the time taken from receiving an alarm to creating a ticket and the duration needed to identify the issue once the ticket has been created.
We break down and analyze each of these indicators, such as:
- Time to Notify (for alarms, varying priorities, and emails)
- Mean Time to Impact Assessment (TTIA)
- Mean Time to Notify a Third-Party
- Time to Answer (for calls and emails)
- Time to Acknowledge (TTA)
- Ticket Update Frequency
By doing so, we offer a more comprehensive, granular view of the entire process that contributes to the MTTR.
So, how does this advanced SLM approach translate into value for clients? In short, it fosters a continuous state of improvement. We take every opportunity to make processes and activities as efficient as possible, whether examining each component of an SLO for areas of potential improvement or introducing automation for incremental enhancements. This continuous refinement contributes to greater availability and less downtime.
With this enhanced approach to SLM, our monthly reports present both precise reporting around key service levels and a broader view of performance. This combined approach allows us to be proactive, informing enhancements and optimization based on a more comprehensive and nuanced understanding of our service performance.
Best Practices for NOC SLA/SLO Reporting
1. Break your SLA/SLOs down into their component parts and report on each of them
Many teams take too shallow of an approach to SLA/SLO reporting. As a result, they find themselves dealing with a few challenges:
- They limit themselves to tracking only a few basic operational service levels and fail to utilize a broader array of valuable service-level measures.
- They approach service-level reporting in a manner that doesn't truly reflect or capture every factor of service quality.
- They struggle to capture and report on service levels accurately.
To tackle these issues and promote Continual Service Improvement (CSI), it's crucial to adopt a more comprehensive approach to SLM. This entails utilizing the SLM framework to set SLA/SLOs and proactively measure and enhance service quality.
To execute SLM, teams need to break down each SLA/SLOs into its components and report on them.
Again, to review, SLOs comprise an SLA. They detail the service, responsibilities, and service level targets the SLA/SLO encompasses. For instance, a NOC service provider might set an SLO defining the response time for phone calls, such as answering phones within an average of 30 seconds over a month or ensuring that the maximum wait time for a call is within five minutes.
This deeper approach to reporting paints a more accurate picture of the quality of service provided, revealing specific ways a team can improve.
💡 INOC recommends: Break down each of your SLAs into the SLOs that comprise them. Analyze how these objectives contribute to the overall SLA/SLO. Then identify the SLIs that comprise each SLO and provide ground-level insight into service performance.
2. Choose the right tools
Selecting the right tools for SLA/SLO monitoring and reporting is critical. Various software solutions can track key performance indicators in real time, generate reports, send alerts for SLA/SLO breaches, and more. Consider factors like ease of use, customization options, integration capabilities, and cost when selecting a reporting tool. The chosen tool should track all critical metrics and present data understandably for you and your clients.
Data visualization tools such as Power BI and Tableau can analyze complex data, presenting it in a digestible way. However, it's crucial to remember that each tool has its strengths. For instance, Tableau excels in analyzing large amounts of data and putting it into categories, but it's not designed for detailed incident scrutiny.
Storage and data delivery tools like Snowflake and Redshift, on the other hand, are optimized for data storage and delivery to front-end platforms. They can be used as data lakes or data warehouses. Keep in mind that considerations like data storage requirements and security vary from one organization to another.
💡 INOC recommends: Utilize each tool for its intended purpose, respecting its strengths and limitations. For example, leverage Tableau for its powerful data bucketing abilities but avoid using it to drill down into specific incidents. Understand your clients' specific requirements around data storage and security, and adapt your tool usage accordingly.
3. Automate repetitive tasks to improve efficiency and reduce wasted labor
Broadening the conversation beyond just reporting for a moment, NOC operations often involve a host of repetitive tasks that can be labor-intensive and time-consuming. Manual tasks not only tie up valuable resources but also open up opportunities for human error. A vital best practice is identifying these tasks and automating them to improve efficiency and minimize the potential for mistakes. You need granular reporting to do this.
Start by breaking down your operations into their component parts. Use reporting to analyze where your team is spending most of its time.
Is there a task that is very manual right now? Could it be automated?
For example, if your team has to manually enter dispatch data into a ticketing system, consider automating this process.
— Peter Prosen, VP of NOC Operations, INOC
💡 INOC recommends: Look at each segment of your operation and think about whether it can be automated. Every time you find a task that's repeated often, automate it to reduce time spent and improve efficiency. Automation not only saves time but also reduces the chance of errors and improves overall service quality. This approach applies to all areas of NOC operations, not just reporting.
4. Conduct regular SLA/SLO review meetings
Regular SLA/SLO review meetings are essential to maintaining open communication and transparency between you and your clients. This proactive approach enables you to discuss performance, address any issues that have arisen, and adjust the SLA/SLO as necessary.
💡 INOC recommends: Hold these review meetings quarterly, whether you think they're necessary or not. This way, you're not just communicating with your clients when there are problems – you're also reaching out when things are going well. Moreover, this strategy helps boost morale within your team, as they're made aware of their successes, not just the challenges or complaints.
You'll want to provide both the good and the bad in these meetings. Review the SLA/SLO reports, discussing any breaches or near-breaches, identify their causes, and figuring out how to avoid such issues in the future. But also highlight successes! For example, if there were 14 client complaints but your team handled 1000 tickets in that same period, point out that the complaints represent less than 1% of the total tickets. This perspective showcases the overall performance and the relative rarity of problems.
Reinforce that while perfection may be unattainable, your team consistently maintains a strong performance record. Regular review meetings are also an opportunity to discuss if the current SLA/SLO metrics are still relevant or if they need to be updated to better align with the evolving needs of the business. This two-way communication fosters a constructive relationship where both successes and failures are recognized and learned from.
A Few Example SLA/SLO Reports from INOC
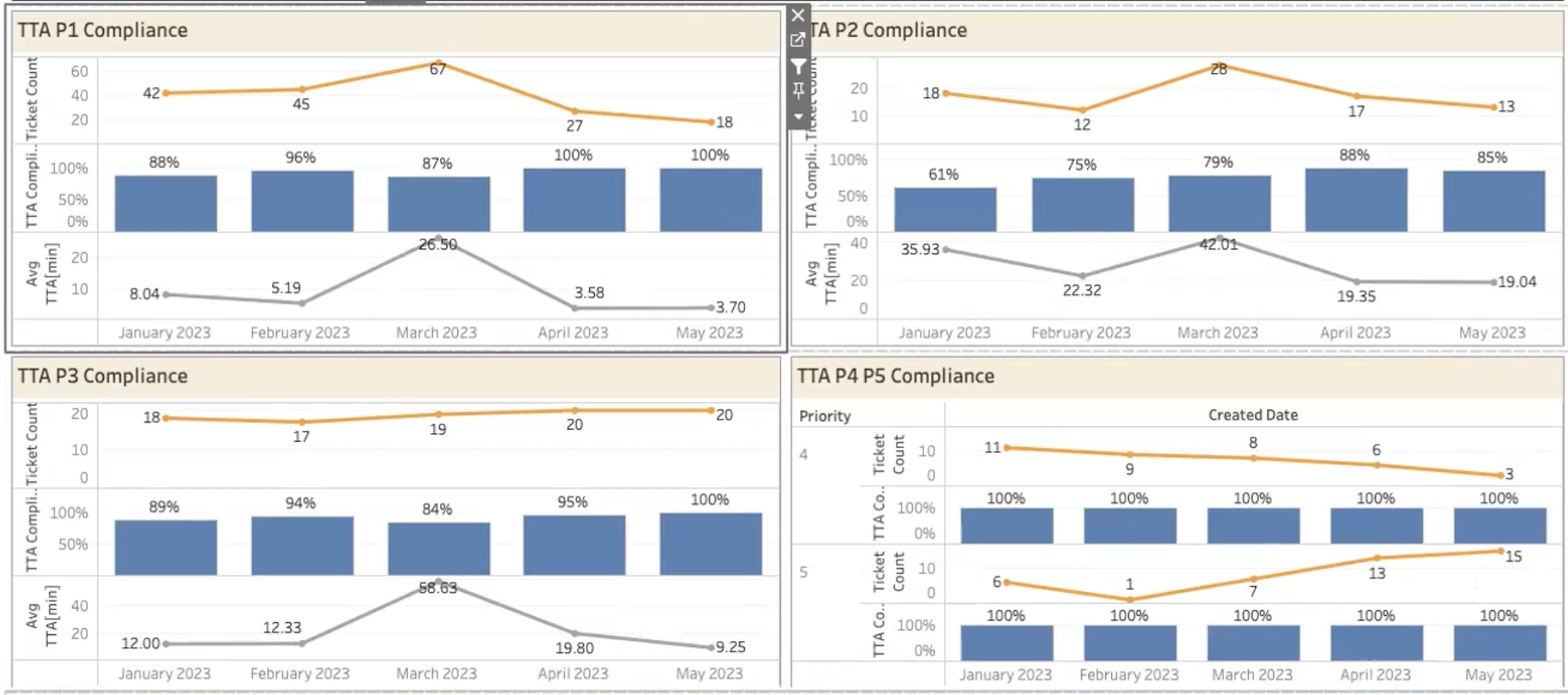
TTA (Time-to-Acknowledge) Compliance
This measures how often a specific performance metric is met. In the example below, P1 TTA was met 100% of the time in May 2023.
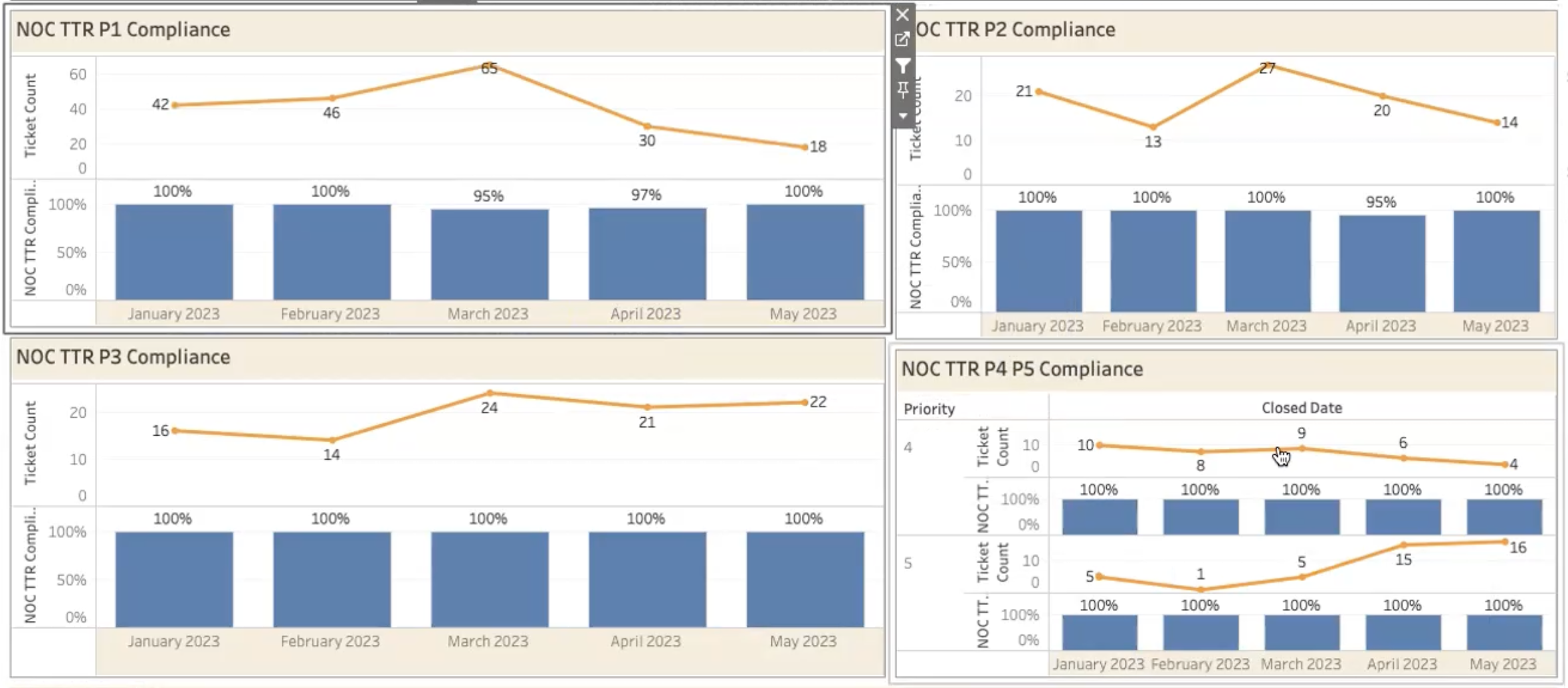
NOC TTR (Time-to-Resolve) Compliance
This is the amount of time the NOC spends resolving an issue, divided by priority level (P1, P2, P3, etc.)
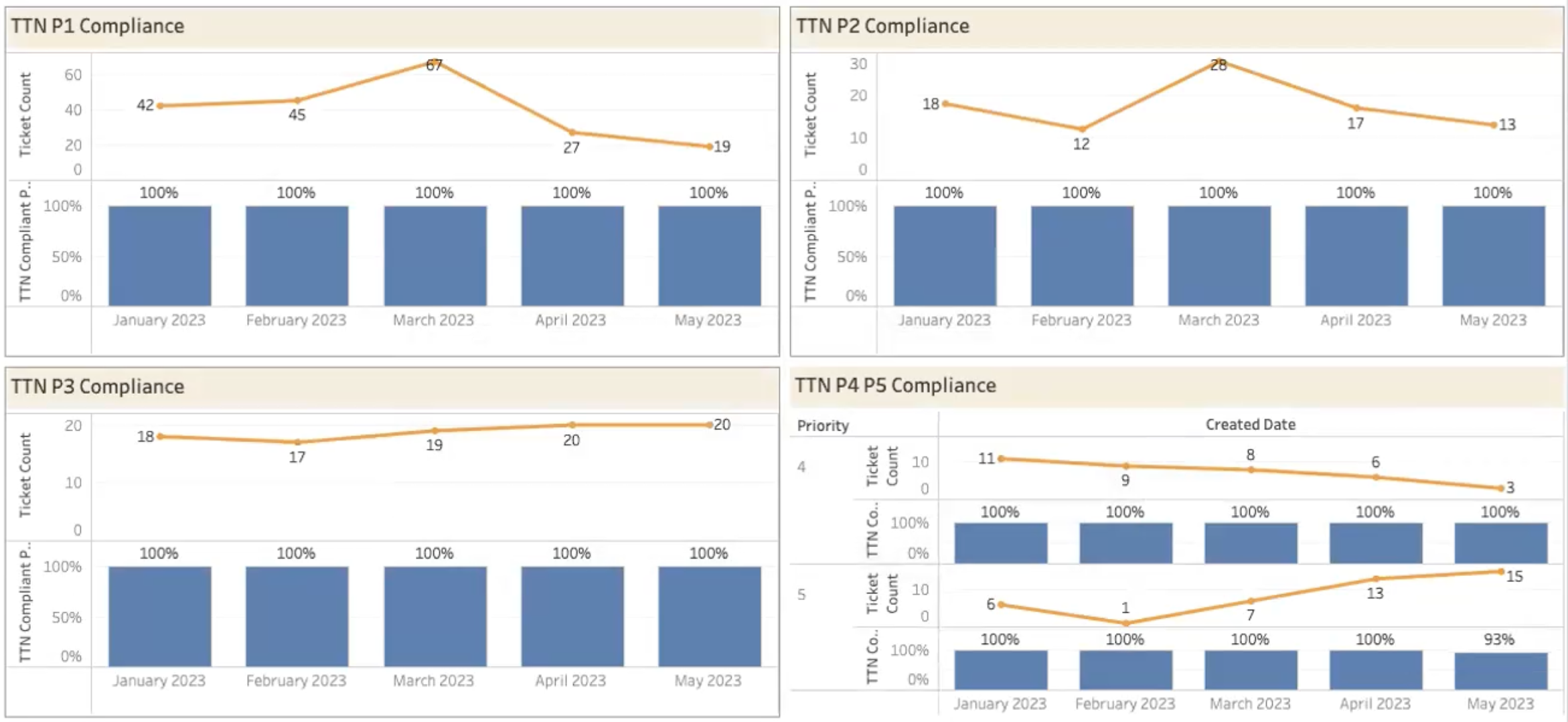
NOC TTN (Time-to-Notify) Compliance
This measures the time it takes for the service to notify about an issue.
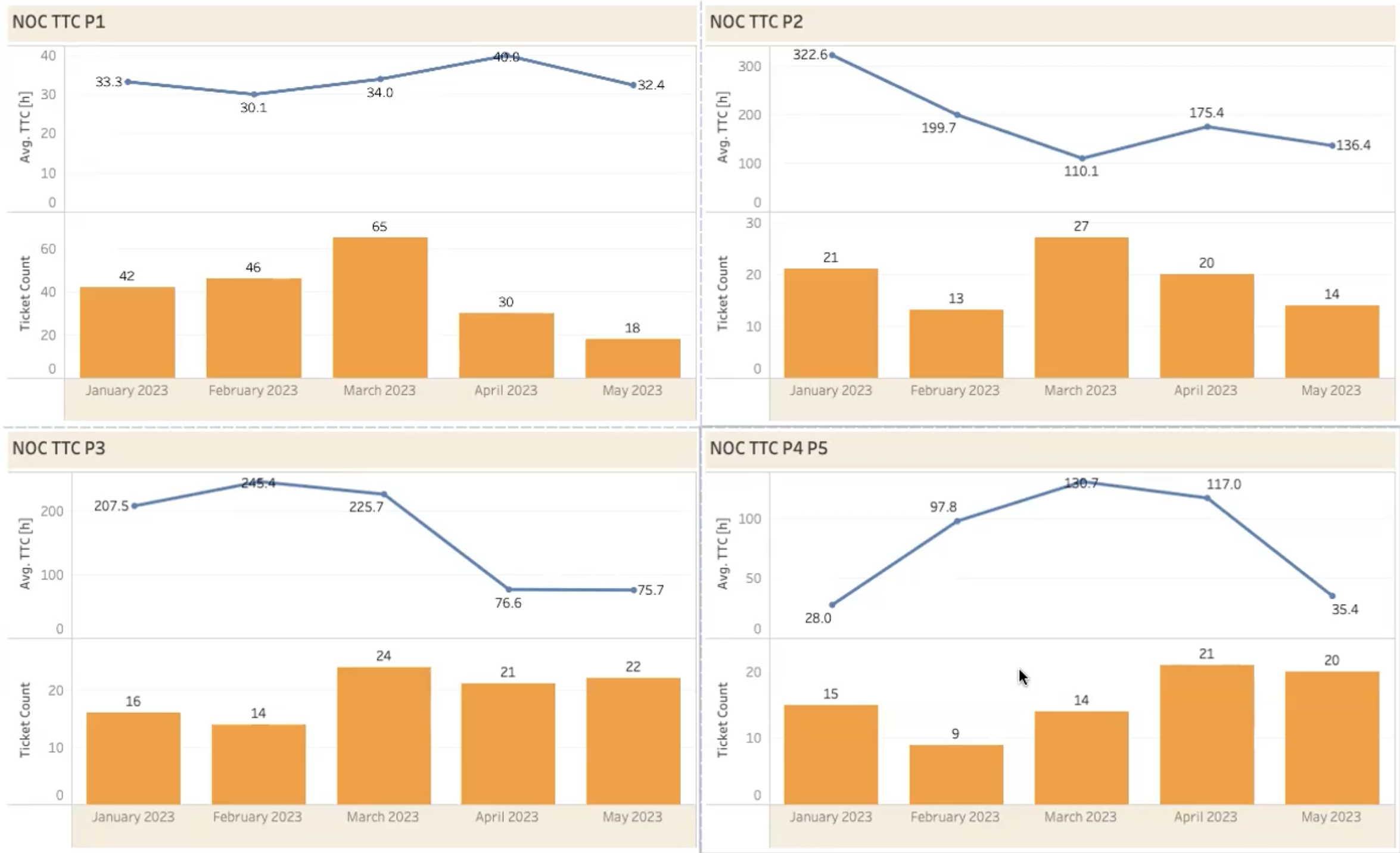
NOC TTC (Time-to-Close)
This calculates the average time it takes to close an incident after it has been resolved.
SLA Exclusions
This measures incidences that are excluded from reporting due to being a duplicate or being caused by maintenance.

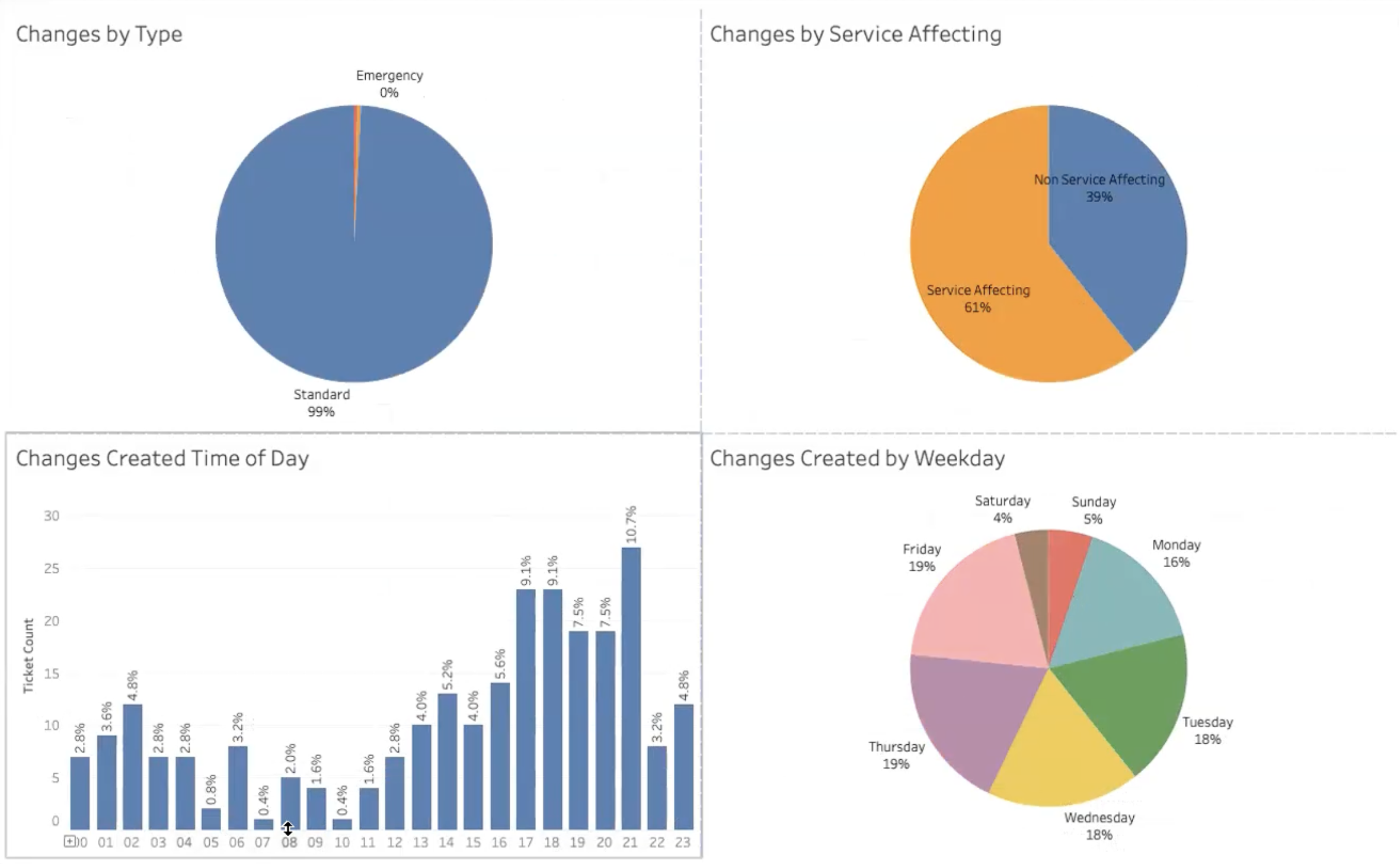
Change Metrics
These monitor changes made, categorizing them as service-affecting or non-service-affecting and breaking them down by time of day and day of the week.
A Better Approach to Service Level Management
A handful of rigid service levels rarely tell the full story about the quality of NOC service you receive. Our SLM model combines critical KPI reporting with a broader, often more meaningful set of objectives that bring additional data and context into view.
With each report, you’ll come away with precise reporting and big picture perspective into every dimension of service. Reports aren’t just handed off. We unpack the details and stay on top of changes within your organization to ensure your service levels directly reflect the support you receive.
Our ITIL-aligned service-level management approach goes beyond the standard SLA to incorporate sophisticated measures into the level of support being delivered. Essential SLOs like response times, average and maximum call hold times, notification and escalation times, and troubleshooting windows are complemented by next-level measures, including time-to-impact assessments, time-to-restore by the responsible party, and many others.
With the flexibility to choose which service levels reflect your measures for success, we help you assemble the SLM package that reflects the specific demands of your IT environment while balancing business goals and budget each step of the way.
Learn more about NOC services and schedule a NOC consultation with our Solution Engineers to start the conversation.
Want to learn more about managing metrics in the NOC, and many other best practices for running a NOC at peak performance? Grab our free white paper below.

Free white paper Top 11 Challenges to Running a Successful NOC — and How to Solve Them
Download our free white paper and learn how to overcome the top challenges in running a successful NOC.






-images-0.jpg?height=2000&name=ino-WP-NOCPerformanceMetrics-01%20(1)-images-0.jpg)








-images-0.jpg?width=200&height=259&name=ino-WP-NOCPerformanceMetrics-01%20(1)-images-0.jpg)
