

Efficient workflows and fast response times are critical to maximizing IT infrastructure performance and uptime—the core goals of any Network Operations Center (NOC).
Whether your infrastructure is running in the cloud, on-premises, or a hybrid of the two, the impact of service unavailability can be disastrous. Your NOC needs to be able to detect and respond to issues within acceptable service levels to ensure the impact on your business is minimal.
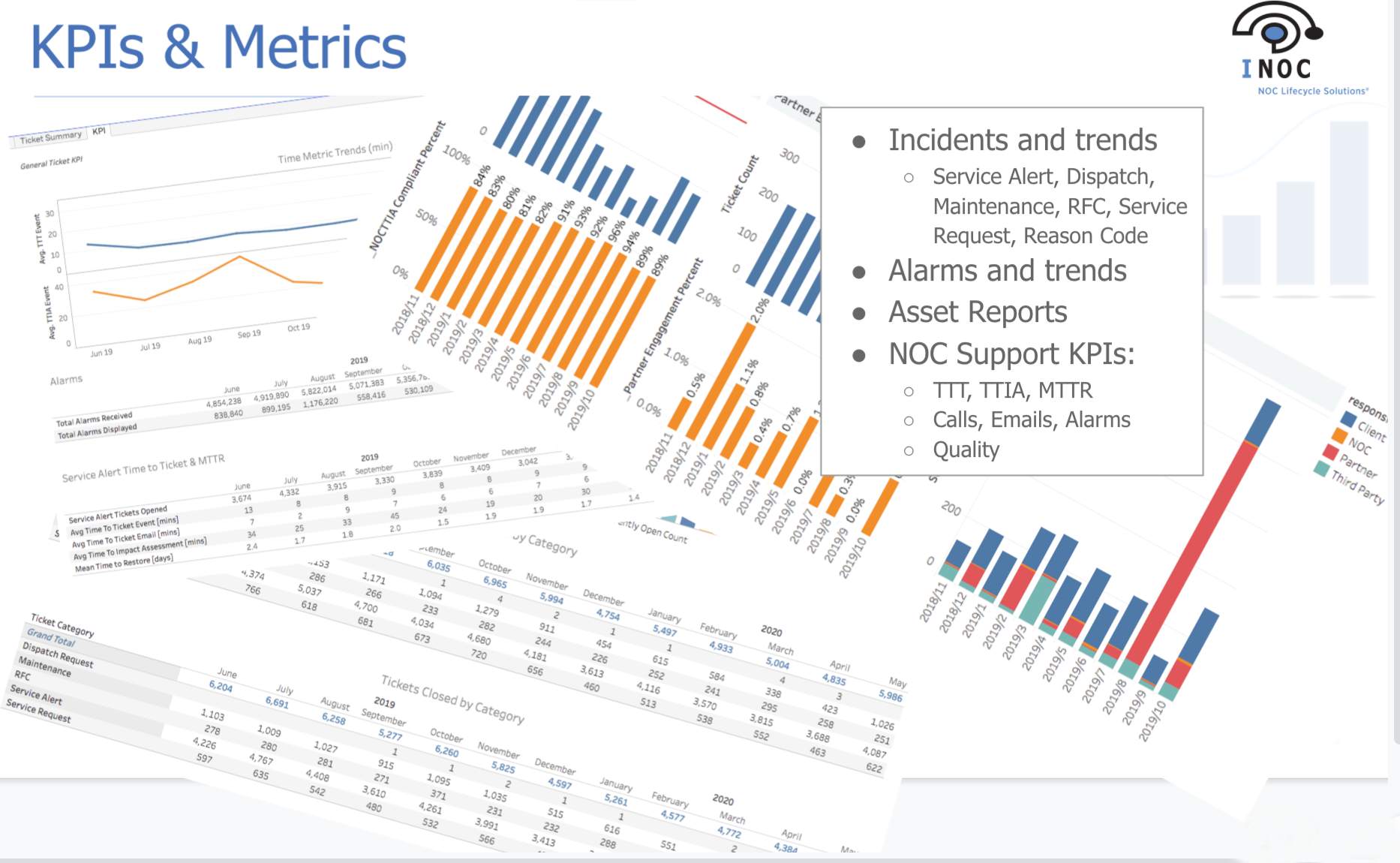
Top-tier NOCs utilize a Service Level Management (SLM) framework to make and measure progress toward these goals. SLM serves as the foundation for gathering service requirements, establishing service levels, and monitoring and reporting performance according to those service levels.
However, implementing an SLM framework to manage NOC service levels isn’t a straightforward process. There’s no handy guidebook for NOCs to follow. As a result, many NOC teams face the following challenges:
- Limiting themselves to the most basic operational service levels without taking full advantage of a much wider array of useful service levels.
- Taking an approach where service level compliance does not reflect the quality of the service.
- Rendering themselves unable to monitor and report on the service levels effectively.
A more comprehensive approach to SLM enables the NOC to paint a complete and accurate picture of the quality of service provided, which enables Continual Service Improvement (CSI).
Applying an SLM framework to the NOC at this level takes thoughtful planning and diligent management. Here at INOC, we’ve tuned this powerful framework to unleash its full potential not only for establishing SLAs but also for measuring and improving service proactively.
Here, we clearly explain SLM concepts relative to the NOC and how NOCs should apply SLM beyond the standard operational measures to provide greater value and achieve better outcomes.
📄 Read our other guide—NOC Service Level Reporting: Basics, Best Practices, and Examples—for a closer look at the reporting side of service level management.
SLM vs. SLA vs. SLO vs. SLI
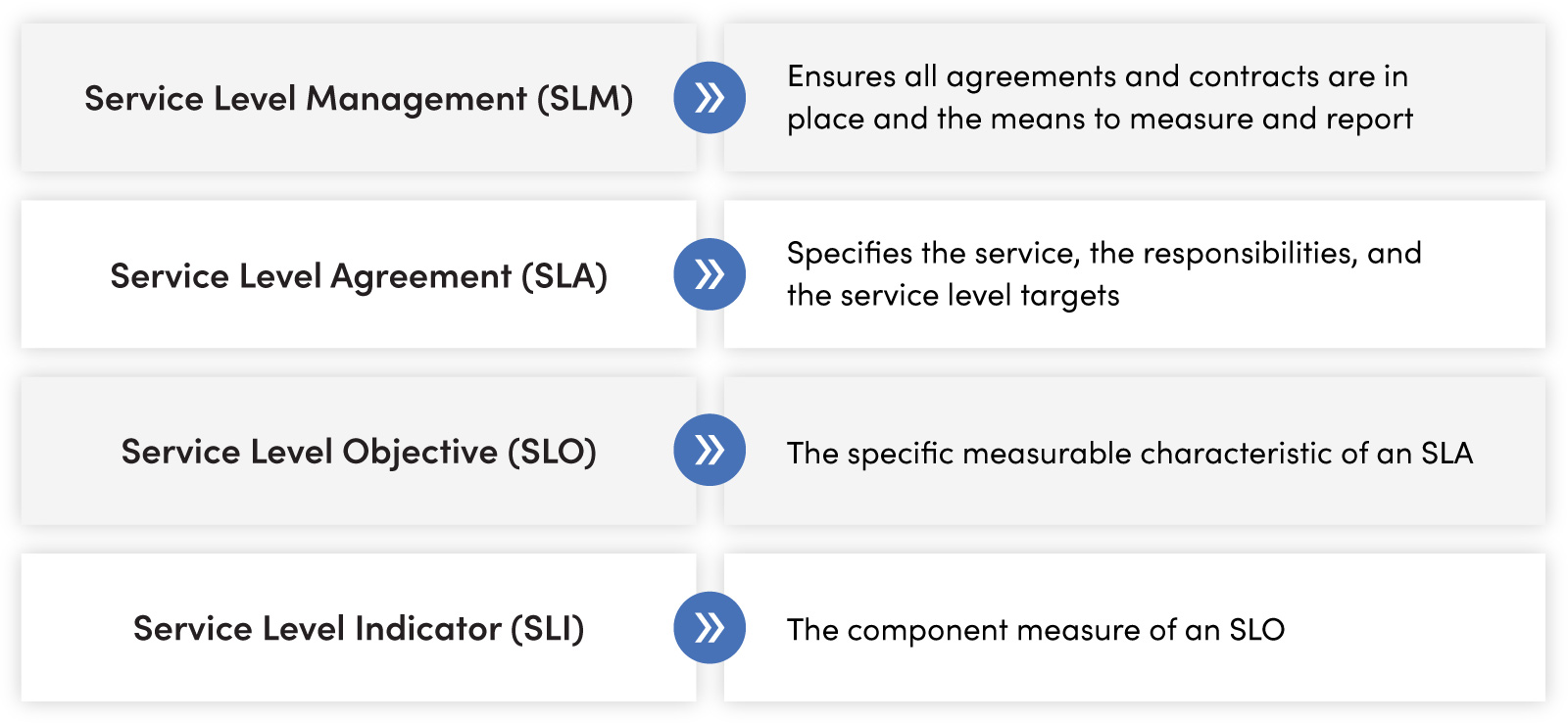
What is Service Level Management (SLM)?
At a high level, Service Level Management is the practice of bringing everyone together in agreement with how IT service is to work. SLM ensures that service levels are measured and reported. Practically speaking, SLM involves defining, documenting, and managing service levels—in this case, in the NOC.
What are Service Level Agreements (SLA)?
To carry out SLM, we must define the performance measures in a Service Level Agreement.
An SLA, at its simplest level, is an agreement between an IT service provider—internal or external—and the customer that ensures certain characteristics that measure the performance of the service are defined. It also establishes the responsibilities, the means to measure, and the reporting cadence on actual outcomes relative to those agreements.
An SLA can contain one or more performance measures called Service Level Objectives for which the service provider is responsible. The SLA also contains reporting responsibilities, credits, and penalties.What are Service Level Objectives (SLO)?
Service Level Objectives (SLO) specify the service, responsibilities, and service level targets that comprise an SLA. In other words, they’re the “substance” of an SLA.
Here’s an example: A NOC service provider may establish an SLO that sets the response time for phone calls. Here, a substantive SLO may be answering the phones in an average of 30 seconds measured over a month. Another SLO, this one for call handling, might indicate that the maximum time that a call can wait to be answered must be within five minutes.
Now that we have some hard objectives defined, we need the means to measure and report on them.
What are Service Level Indicators (SLI)?
Service Level Indicators are the components of an SLO. An example is shown below.
- (SLO) Time to Notify for alarms = (SLI) Time elapsed between alarm generation and alarm receipt + (SLI) Time delay until either automation or NOC engineer starts addressing the alarms + (SLI) Time duration to create the Incident record
Each of the SLIs can be measured, and in total, they reflect the SLO. These measures provide actual insight into the performance level of the NOC to comply with the SLO.
Service Level Management in the NOC
So, how do these IT service concepts apply specifically to the NOC? SLAs are the formal agreements that document service level targets and specify the responsibilities between a NOC and its customers.
Most ITIL-aligned NOCs utilize SLM for establishing, monitoring, and reporting on the standard service levels expected of basically any NOC. These include response times, average and maximum call hold times, notification and escalation times, and troubleshooting windows.
An Advanced Approach to NOC Service Level Management
Here at INOC, we complement standard KPI reporting, which includes monthly SLA measurements, with an array of additional SLOs to better measure performance and keep both teams aligned on success.
In our view, limiting reporting to just a handful of rigid service levels rarely tells the full story about the quality of NOC service being provided. Limited reporting also ignores important operational signals that serve as inputs for continual improvement.
Our SLM model combines critical KPI reporting with a broader, often more meaningful set of objectives that bring additional data and context into view. In short, we analyze each SLO, break them into their components, and measure each of those. Rather than focusing on a composite metric, we focus on addressing and optimizing each of its component parts.
Take the critical SLO of Mean Time to Restore (MTTR) set at four hours, for example. This measure contains several more granular SLIs:
- How long did it take from an alarm being received to a ticket being created?
- How long did it take to determine the problem once the ticket was created?
We break down and address each discrete indicator that, together, comprise MTTR.
These include:
- Time to Notify (for alarms and various priorities)
- Time to Notify (for email)
- Mean Time to Impact Assessment (TTIA)
- Mean Time to Notify Third-Party
- Time to Answer (for calls and emails)
- Time to Acknowledge (TTA)
- Ticket Update Frequency
So, how does this approach to SLM translate into tangible value for a client? Put simply, it drives a constant state of continual improvement. We want to take every opportunity to make processes and activities as efficient as possible. That means closely examining each component of an SLO, spotting those opportunities, and, for example, adding automation to make incremental improvements that contribute to greater availability and less downtime.
With this expanded approach to SLM, each monthly report we produce presents both precise reporting around key service levels and a big picture perspective that can inform proactive enhancements and optimization.
NOC Service Level Management in Action: 2 Examples from the Field
Describing the function and value of SLM in the NOC is one thing. Demonstrating it by example is another. We summarized two instances of SLM in action below to bring the concept down to earth and into the NOC.
Both examples demonstrate the value of going beyond the basic SLOs (like those shown in this example dashboard) to understand what specific factors are contributing to them.
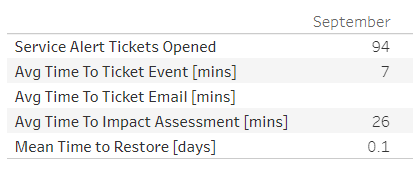
Example #1: Disk Write IOPS Spike on Amazon EC2
Shortly after turning up a monitoring service for a client’s AWS infrastructure, an alert is raised to the NOC. The Disk Write Input/Output Operations Per Second (IOPS) had risen significantly.
Thanks to automation, the alert was received in the NOC virtually instantly. But once there, like any alert, the alert response must be measured.
Alarm to Ticket
- The first response is acting on the alarm—in this case, ticketing and initial notification.
- An SLO in place within the Incident Management SLA indicates that critical alarms must be handled within 15 minutes from the time of receipt of the event to ticketing.
- The NOC can ticket this event in five minutes. This SLI signals that the NOC has performed well above the objective set out. The NOC team pats itself on the back for a job well done.
Diagnosis and Response
Now that the event is ticketed, the NOC team needs to get to work determining what happened so they can direct the correct response and restore the service:
- The response for this type of event is guided by a provision: critical incidents like this one have an SLO mandating a 15-minute response time. (This is the time from when the event was ticketed until the time a NOC engineer is actively diagnosing the issue.)
- Again, the NOC logs an SLI on this ticket of seven minutes to dive into the issue. Another round of applause for the NOC.
Restoration
While the NOC diagnosed this issue exceedingly fast, the IOPS continued to remain high 12 minutes after the alert came in. Cue service restoration:
- The NOC engineer has a few developer-provided scripts they can run to try to resolve the issue before having to trigger an escalation.
- The Incident Management SLA has another SLO covering this type of self-driven NOC time to repair: Mean Time to Repair (MTTR). (This is the total time from when the NOC was notified to when the event was resolved.)
- If the NOC team can handle this incident completely independently (without third-party or outside engineering support), the SLO the customer has in place for the NOC is four hours.
- The NOC engineer, upon logging onto the web server, can check the status of the instance in the AWS Management Console, run a script to report the issue to Amazon on the EC2 instance and run another script that triggers the teardown and rebuild of the instance.
- As the instance was well load-balanced within the AWS infrastructure, end-users detected no application impact, and the rebuild of the instance resolved the issue.
This whole process took the NOC engineer about 45 minutes to complete. Since this was handled within the NOC and the MTTR on this incident was 57 minutes, the NOC was well within the four-hour SLO.
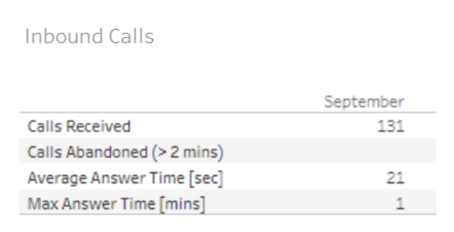
Example #2: Retail Location is Unable to Process Credit Cards
It’s ten o'clock in the morning, and a NOC-supported retail location finds itself unable to process credit card transactions. The store manager calls the NOC for support.
Call to Ticket
- The phone is answered in the NOC within 25 seconds. The NOC is already off to a great start, as the service SLO for answering the phone is to do so within 60 seconds of the call reaching the NOC.
- After some back and forth on the phone, the initial NOC engineer cannot resolve the issue with the store manager. They open a ticket and provide a ticket number.
- The NOC engineer logs the ticket as a Priority 1 (Critical) ticket and moves to loop in the next level of support.
Escalation
- The NOC engineer escalates the ticket to the next level of support within the NOC to a Tier 2 NOC engineer.
- For a Priority 1 ticket, the SLO for the next level of support is 15 minutes, and the Tier 2 NOC engineer picks up this ticket in 12 minutes.
Diagnosis
- In this case, the site has an SD-WAN device, and the NOC engineer can access the orchestrator and immediately sees that the site is consuming about 90% of its available bandwidth. The NOC engineers find this unusual, looking at the utilization numbers for the past two hours and see that the spike started about 20 minutes ago.
- Looking at the traffic flowing out from the site, the NOC engineer observes a high amount of traffic heading for an online streaming service. The NOC engineer also observes that there is no traffic flow that would give priority to the credit card machine traffic.
- Logging all of these details into the ticket, the NOC engineer concludes that a change is required to prioritize the credit card machine traffic. At this point, another 15 minutes have passed during this initial investigation.
Resolution
- Normally, the NOC maintains a four-hour SLO for MTTR when resolving a Critical ticket if they can do so independently. However, this issue requires an escalation to a third party outside the NOC’s control. (This demonstrates the importance of having appropriate response SLOs in place with vendors besides the NOC!)
- Fortunately, the third-party vendor can make a quick change via the SD-WAN orchestrator for that site. Looking at its traffic flows, both the NOC engineer and the third-party engineer agree the issue was resolved.
- The support contract dictates that a Critical issue response time with this third-party vendor is 30 minutes. In this case, it took about another 15 minutes. The NOC can now reach out to the store manager and confirm that the issue was, in fact, resolved.
In this case, the NOC could quickly resolve the issue because the correct SLOs were in place.
Summary, Final Thoughts, and Next Steps
These examples show how SLM is key to measuring, quantifying, and ensuring the NOC performs to its full potential.
Beyond these functions, it’s also essential to understand how the service levels established and managed through SLM will impact the response time needed for various scenarios.
SLM is instrumental in tracking, reporting, and reviewing these services' performance to understand better every dimension of the service being provided and improve the performance for handling the next incident.
For IT leaders considering SLM in the context of their own IT service, the following questions can be illustrative of the need for action:
- When was the last time you reviewed your SLA agreement with your NOC?
- Do you or your service provider’s current approach to SLM go far enough to paint a complete picture of NOC performance?
- Do you or your service provider’s current approach to SLM provide sufficient reporting to contribute to continual improvement activities?
- Do you have the correct—and enough—SLOs in place to fully track the performance of your NOC operation? Are there performance blindspots?
- Do plans for future IT service projects require you to revisit and potentially enhance your approach to SLM?
Not satisfied with answers to these questions, or need help working through the correct Service Level Management components for your organization? Schedule a free NOC consultation or contact us to see how we can help you improve your IT service strategy and NOC support.
Want to learn more about building, optimizing, and managing your NOC for maximum uptime and performance? Grab our free white paper below.

Free white paper Top 11 Challenges to Running a Successful NOC — and How to Solve Them
Download our free white paper and learn how to overcome the top challenges in running a successful NOC.






-images-0.jpg?height=2000&name=ino-WP-NOCPerformanceMetrics-01%20(1)-images-0.jpg)








-images-0.jpg?width=200&height=259&name=ino-WP-NOCPerformanceMetrics-01%20(1)-images-0.jpg)
